
- Researchers introduce Quiet Self-Taught Reasoner (Quiet-STaR) to enhance language models’ (LMs) reasoning capabilities.
- Quiet-STaR embeds reasoning directly into LMs by generating internal rationales for processed text fragments.
- This innovative approach diverges from previous methods by fostering universal reasoning abilities across diverse text datasets.
- The model generates rationales in parallel, blending internal reflections with predictions to improve comprehension and response generation.
- Reinforcement learning optimizes the process, enhancing the model’s performance on challenging reasoning tasks without task-specific fine-tuning.
- Quiet-STaR’s success in improving LM performance heralds a new era for intelligent and adaptable language models.
Main AI News:
In the pursuit of artificial intelligence capable of emulating human reasoning, researchers are dedicated to augmenting language models (LMs) to process and produce text with a depth of comprehension akin to human cognition. While LMs excel at discerning patterns in data and generating text based on statistical probabilities, they often fall short when tasked with navigating the intricacies of reasoning or extrapolating insights beyond explicit information. This disparity between human and machine cognition becomes most evident in tasks requiring the interpretation of implicit meanings or the generation of insights not overtly stated in the input text.
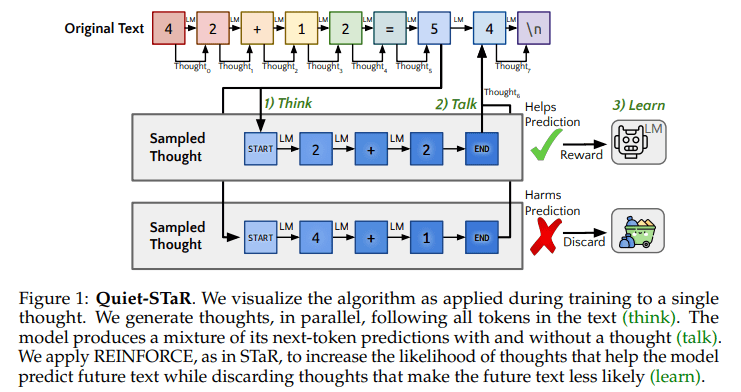
Researchers from Stanford University and Notbad AI Inc. introduce Quiet Self-Taught Reasoner (Quiet-STaR), a revolutionary paradigm shift aimed at integrating reasoning directly into the framework of LMs. This pioneering approach revolves around the model’s capacity to generate internal reflections or rationales for each text fragment it processes, enabling it to engage in reasoning more akin to human thought processes. Quiet-STaR encourages the model to generate rationales for every token encountered, prompting it to pause and contemplate, resembling the reflective pause of a human considering their next utterance, before proceeding.
This methodology diverges markedly from previous endeavors, which often relied on training models on specific datasets tailored to enhance reasoning for particular tasks. While effective to some degree, such approaches inherently constrain the model’s ability to apply reasoning universally. Quiet-STaR transcends these limitations by fostering the model’s proficiency in generating rationales across a diverse array of texts, thereby broadening the spectrum of its reasoning capabilities.
The model concurrently generates rationales across processed text, integrating these internal reflections with its predictions to enhance comprehension and response generation. This process is honed through reinforcement learning, refining the model’s discernment of which reflections are most conducive to predicting future text. Demonstrations by the researchers showcase that this technique substantially improves the model’s performance on challenging reasoning tasks, such as CommonsenseQA and GSM8K, obviating the need for task-specific fine-tuning. These findings underscore Quiet-STaR’s potential to universally enhance reasoning in language models.
By endowing language models with the capacity to generate and leverage their rationales, this research enhances their predictive accuracy and elevates their reasoning prowess to unprecedented heights. The success of this technique in augmenting model performance across diverse reasoning tasks, without necessitating task-specific adjustments, heralds a new era for intelligent and adaptable language models.
Conclusion:
The introduction of Quiet-STaR marks a significant advancement in the field of language models, enhancing their reasoning capabilities without the need for task-specific adjustments. This innovation holds promise for various industries relying on AI-driven text processing, paving the way for more accurate and insightful applications across diverse domains.