
- Researchers explore effective strategies using GPT-4 and open-source methods for controlling language proficiency in AI-generated content.
- Methods include few-shot prompting, supervised finetuning, and reinforcement learning (PPO) to align outputs with CEFR standards.
- Proposed CEFR-Aligned Language Model (CALM) integrates finetuning and PPO, reducing costs while maintaining quality.
- CALM utilizes datasets like TinyTolkien to train models on various CEFR levels, enhancing proficiency control.
- Evaluation metrics demonstrate CALM’s comparable performance to GPT-4 with improved cost efficiency and quality ratings.
Main AI News:
Researchers from Stanford and Duolingo showcase effective strategies for generating content at desired proficiency levels using proprietary models like GPT-4 and open-source techniques. Controlling language proficiency in texts from large language models (LLMs) remains a pivotal AI challenge, particularly for applications in education and language learning where varying proficiency levels are crucial. Without precise proficiency control, LLM-generated content may not be suitable for non-native speakers or learners.
Current methodologies address this challenge through few-shot prompting, supervised finetuning, and reinforcement learning (RL). Few-shot prompting involves guiding the model with examples, while supervised finetuning adapts the model using labeled data. RL techniques, specifically Proximal Policy Optimization (PPO), further refine outputs based on rewards. However, these methods face limitations such as high computational costs, suboptimal performance with open-source models, and the need for extensive labeled data.
To address these issues, Stanford and Duolingo propose the CEFR-Aligned Language Model (CALM), integrating finetuning and PPO to align output proficiency levels with Common European Framework of Reference for Languages (CEFR) standards. CALM bridges the performance gap between proprietary and open-source models, enabling cost-effective, high-quality proficiency-controlled content generation.
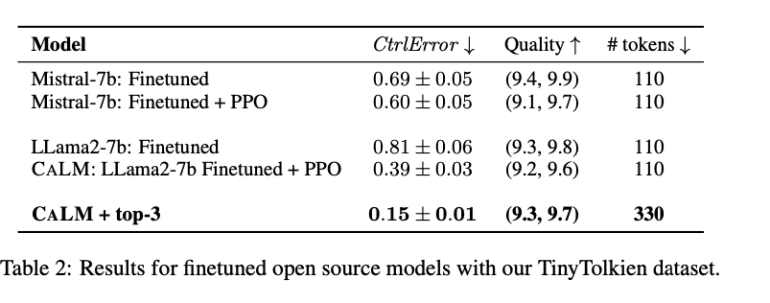
This approach involves finetuning open-source models like LLama-2-7B and Mistral-7B using the TinyTolkien dataset, consisting of short stories spanning various CEFR levels. PPO training further ensures that model outputs match desired proficiency levels. Additionally, a sampling strategy enhances performance by selecting optimal outputs from multiple generations. Technical components include leveraging linguistic features for automated CEFR scoring and employing RL techniques to minimize ControlError, which quantifies deviation from target proficiency levels.
CALM demonstrates comparable ControlError to GPT-4 with reduced costs, validated through comprehensive evaluation metrics including ControlError, QualityScore, and computational efficiency. Both automated scoring and human studies confirm high ratings for quality and proficiency alignment. CALM’s superior performance is highlighted in comparison tables, where CALM with top-3 sampling achieves a ControlError of 0.15, surpassing other models and strategies.
Conclusion:
Stanford and Duolingo’s CALM approach marks a significant advancement in AI-driven language proficiency control. By integrating sophisticated techniques like finetuning and reinforcement learning, CALM not only enhances the quality and precision of AI-generated content but also reduces operational costs. This development signifies a crucial step forward for markets reliant on AI-generated text, particularly in education and language learning sectors where tailored proficiency levels are imperative for effective communication and learning outcomes.