
- SEED-X, developed by Tencent AI Lab and ARC Lab, addresses challenges in multimodal AI.
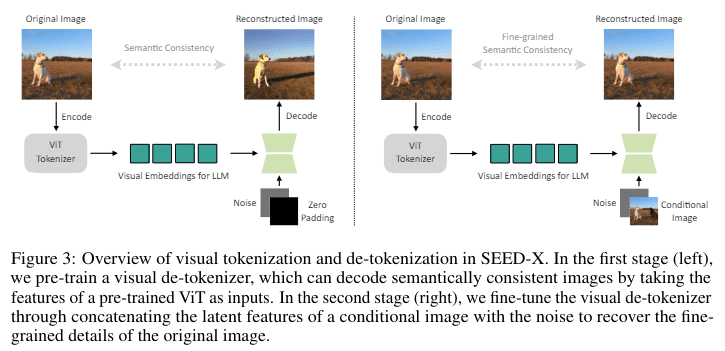
- It integrates a sophisticated visual tokenizer and a multi-granularity de-tokenizer.
- SEED-X excels in generating images from textual descriptions with high fidelity.
- Demonstrates significant performance improvements over traditional models.
- Broadens applicability in real-world scenarios with dynamic resolution image encoding.
Main AI News:
In the realm of artificial intelligence, the quest for models capable of seamlessly processing diverse data types has been paramount. These multimodal architectures aim to decode and generate insights from an array of inputs, including text, images, and audio, emulating the intricate workings of the human mind.
A pivotal challenge lies in crafting systems that not only excel in singular tasks like image recognition or textual analysis but also possess the prowess to amalgamate these proficiencies for tackling intricate interactions across modalities. Traditional paradigms often falter when confronted with tasks demanding a harmonious fusion of visual and textual comprehension.
Historically, models have grappled with the dichotomy of specializing in either textual or visual domains, leading to a compromise in performance when confronted with the intersection of the two realms. This dilemma becomes palpable in scenarios necessitating the generation of content blending textual and visual elements seamlessly, such as automatically crafting descriptive narratives for images that authentically encapsulate their visual essence.
Enter SEED-X, the brainchild of researchers from Tencent AI Lab and ARC Lab, Tencent PCG, heralding a breakthrough in surmounting the aforementioned obstacles. Building upon its predecessor, SEED-LLaMA, SEED-X integrates novel features, facilitating a holistic approach to processing multimodal data. Leveraging a sophisticated visual tokenizer and a multi-granularity de-tokenizer, this avant-garde model transcends boundaries to comprehend and generate content across diverse modalities.
SEED-X emerges as the harbinger of a new era in multimodal comprehension and generation, boasting dynamic resolution image encoding and a pioneering visual de-tokenizer capable of reconstructing images from textual descriptions with unparalleled semantic fidelity. Its capability to navigate images of varying sizes and aspect ratios vastly enhances its utility across real-world applications.
The prowess of SEED-X extends across a spectrum of applications, effortlessly conjuring images mirroring their textual counterparts and demonstrating an intricate grasp of the intricacies inherent in multimodal data. Performance benchmarks underscore its superiority, with SEED-X eclipsing traditional models by a notable margin, achieving unprecedented milestones in multimodal tasks. Notably, in evaluations involving the integration of image and text, SEED-X showcased a remarkable performance surge of nearly 20% compared to antecedent models. The comprehensive capabilities of SEED-X underscore its potential to revolutionize AI applications. By fostering nuanced interactions across disparate data types, SEED-X lays the groundwork for pioneering applications spanning automated content creation to enriched interactive user experiences.
Conclusion:
SEED-X’s emergence represents a significant leap forward in the realm of multimodal AI. Its prowess in seamlessly integrating visual and textual data sets a new standard for performance and opens up avenues for innovative applications across various industries, promising transformative changes in the market landscape.