
- Recent Text-to-SQL methodologies use deep learning models, particularly Seq2Seq models, to map natural language to SQL outputs.
- Large language models (LLMs) offer significant improvements due to their vast parameter sets and ability to capture complex data patterns.
- A study from Peking University explores converting natural language queries to SQL using LLMs.
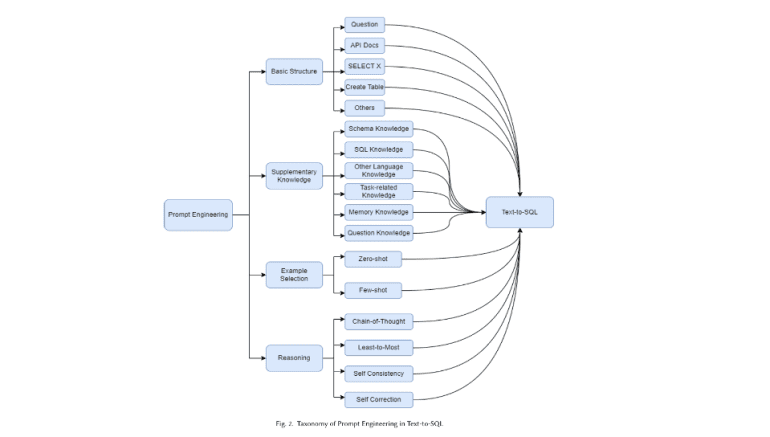
- The study proposes two main strategies: prompt engineering (e.g., RAG, few-shot learning) and fine-tuning with task-specific data.
- Various multi-step reasoning techniques, such as Chain-of-Thought and Self-Consistency, are applied to enhance SQL query accuracy.
- The integration of LLMs has increased accuracy on benchmarks like Spider from 73% to 91.2%.
- Challenges remain with new datasets like BIRD and Dr.Spider, showing advanced models like GPT-4 face accuracy issues.
- The research highlights the potential of LLMs to improve database interactions for non-experts.
Main AI News:
Recent advancements in Text-to-SQL methodologies have primarily utilized deep learning models, notably Sequence-to-Sequence (Seq2Seq) models, which map natural language inputs to SQL outputs directly. These models, bolstered by pre-trained language models (PLMs), have set new benchmarks in the field due to their extensive training on large datasets, enhancing their linguistic capabilities. However, the advent of large language models (LLMs) presents an opportunity for even greater performance improvements due to their sophisticated scaling laws and emergent abilities. With their vast parameter sets, LLMs can discern complex patterns in data, positioning them as highly effective for Text-to-SQL tasks.
A recent study from Peking University tackles the challenge of transforming natural language queries into SQL queries, a crucial process for enabling non-experts to interact with databases. Given the complexity of SQL syntax and the nuances of database schemas, this task represents a significant hurdle in natural language processing (NLP) and database management.
The study proposes utilizing LLMs for Text-to-SQL through two primary approaches: prompt engineering and fine-tuning. Prompt engineering incorporates techniques such as Retrieval-Augmented Generation (RAG), few-shot learning, and reasoning, which, while requiring less data, may not always achieve optimal results. Conversely, fine-tuning LLMs with domain-specific data can markedly enhance performance but necessitates a larger training dataset. The research evaluates these strategies to determine the most effective method for maximizing LLM performance in generating precise SQL queries from natural language inputs.
The study also delves into various multi-step reasoning techniques applicable to LLMs for Text-to-SQL tasks. These include Chain-of-Thought (CoT), which helps LLMs generate answers incrementally by breaking down tasks; Least-to-Most, which simplifies complex problems into manageable sub-tasks; and Self-Consistency, which utilizes majority voting to select the most frequently generated answer. Each approach aids LLMs in producing more accurate SQL queries by emulating human problem-solving processes.
Performance-wise, the integration of LLMs has markedly improved Text-to-SQL task accuracy. For instance, accuracy on benchmark datasets like Spider has increased from about 73% to 91.2% with LLMs. However, challenges persist, particularly with new datasets like BIRD and Dr.Spider, which introduce more intricate scenarios and robustness tests. The research highlights that even advanced models like GPT-4 face difficulties with certain perturbations, as evidenced by a 54.89% accuracy rate on the BIRD dataset. This reveals the necessity for continued research and development.
Overall, the study provides a thorough examination of using LLMs for Text-to-SQL tasks, showcasing the potential of multi-step reasoning patterns and fine-tuning strategies to enhance performance. By addressing the complexities of natural language to SQL conversion, this research facilitates more accessible and efficient database interactions for non-experts. The proposed methods and their evaluations mark significant progress in the field, promising improved accuracy and efficiency for real-world applications. This work underscores the importance of leveraging LLM capabilities to bridge the gap between natural language understanding and database querying.
Conclusion:
The advancements in LLM-based Text-to-SQL methodologies are set to transform database querying by significantly improving accuracy and usability. The ability of LLMs to handle complex data patterns and enhance natural language understanding offers substantial benefits for making database interactions more accessible to non-experts. As LLMs continue to evolve, they will likely drive further innovations in database management and natural language processing, positioning themselves as critical tools for future advancements in these fields. This progress underscores the importance of ongoing research and development to overcome existing challenges and fully leverage the potential of LLMs in real-world applications.