
TL;DR:
- Agent Bench, a cutting-edge benchmarking tool, is transforming the evaluation of AI’s large language models (LLMs).
- It treats LLMs as agents and offers a comprehensive analysis of their performance, with ChatGPT-4 leading the pack.
- Agent Bench is an open-source platform accessible to a wide range of users, evaluating models across eight diverse environments.
- The Open LLM Leaderboard monitors and ranks open LLMs and chatbots, streamlining the evaluation process.
- Its powerful backend, Eleuther AI’s Language Model Evaluation Harness, ensures accurate and objective performance measurement.
- The tool’s transparency and thorough evaluation process empower the AI community with valuable insights.
- Agent Bench’s impact includes improved AI systems, greater transparency, and accelerated development cycles.
Main AI News:
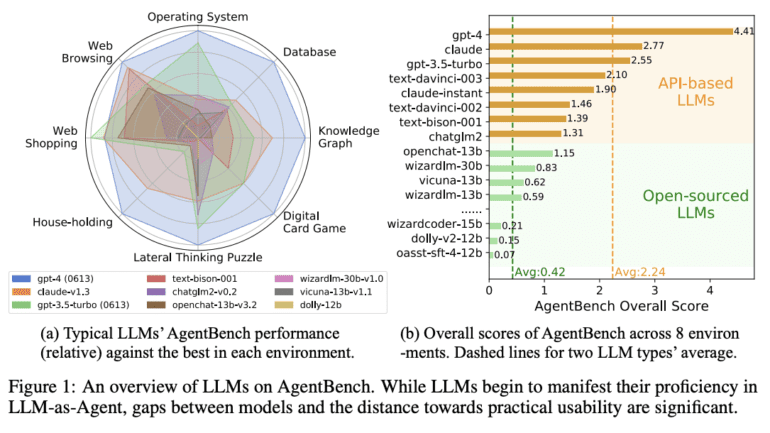
In the realm of benchmarking AI’s large language models (LLMs), a groundbreaking tool named Agent Bench has risen to prominence, promising to reshape the landscape. This innovative platform has redefined the assessment of large language models, treating them as agents and delivering an exhaustive analysis of their capabilities. Agent Bench’s recent debut has sent ripples through the AI community, casting a spotlight on ChatGPT-4 as the reigning champion among these expansive language models.
However, Agent Bench is not merely a tool; it represents an industry revolution. This open-source software can be effortlessly downloaded and utilized on desktops, making it accessible to a broad spectrum of users. The tool’s versatility shines through its capacity to evaluate language models across eight distinct environments. From operating systems to web shopping, it spans a comprehensive range of scenarios, showcasing its adaptability and robustness.
The Vanguard of Open LLM Leaderboard
A transformative initiative, the Open LLM Leaderboard, has taken flight with the mission of continually monitoring, ranking, and dissecting open Language Learning Models (LLMs) and chatbots. This innovative platform has streamlined the evaluation and benchmarking process, allowing developers to submit models for automated assessment on a GPU cluster through a dedicated “Submit” interface.
What distinguishes the Open LLM Leaderboard is its formidable backend powered by the Eleuther AI Language Model Evaluation Harness. This cutting-edge system’s computational prowess is unmatched, accurately generating benchmarking metrics that provide an impartial gauge of language learning models and chatbots’ performance levels.
For the latest insights, the Hugging Face website unveils the Open LLM Leaderboard. As of now, the garage-bAInd/Platypus2-70B-instruct holds its reign at the summit. Additionally, other notable resources like the AlpacaEval Leaderboard and MT Bench offer valuable performance data on current LLM models.
Empowering Progress: Agent Bench’s Role
AgentBench, a remarkable innovation, steps onto the stage as a benchmarking tool meticulously crafted to evaluate Language Learning Models (LLMs)’ accuracy and performance. In the rapidly evolving technology landscape, this AI-focused tool stands as a beacon of progress, addressing the growing demand for sophisticated artificial intelligence products.
By presenting quantifiable data on LLMs’ functional prowess, this benchmarking tool equips developers and teams to identify potential areas of enhancement, driving the evolution of artificial intelligence technologies. Beyond scrutinizing existing models, AgentBench facilitates the design and testing of new AI systems, propelling innovation further.
Transparency is paramount in this endeavor, as AgentBench fosters open and accountable evaluations of LLMs, demystifying the “black box” nature of AI. This clarity empowers the public to engage, understand, and evaluate these intricate technologies more effectively.
In a competitive market, solutions like AgentBench play a pivotal role. Its launch marks a monumental stride in AI technology, poised to redefine language learning models’ application across domains like virtual assistance, data analysis, scientific research, and beyond.
Comprehensive Insight: Agent Bench’s Evaluation Process
The benchmarking tool’s evaluation process is meticulous and all-encompassing. It probes a model’s comprehension of user input, its contextual awareness, information retrieval capabilities, and linguistic fluency. This holistic approach ensures that the tool provides a well-rounded assessment of a model’s capabilities.
The performance of 25 diverse large language models, including those from OpenAI, Claude models by Anthropic, and Google models, has already been scrutinized by Agent Bench. These evaluations have brought to light the proficiency of these models as agents while also highlighting the performance disparities among them.
To leverage Agent Bench, users require essential tools like an API key, Python, Visual Studio Code, and Git. Armed with these tools, one can evaluate a model’s performance across a spectrum of environments, spanning operating systems, digital card games, databases, household tasks, web shopping, and web browsing.
Charting New Territories: Transforming LLM Evaluation
Agent Bench emerges as an avant-garde tool poised to revolutionize the evaluation of large language models. Its exhaustive, multi-environment assessment approach, coupled with its open-source nature, positions it as a prized asset in the AI landscape. As it continues to evaluate and rank models, it is poised to deliver invaluable insights into large language models’ capabilities and potential as agents.
More than a technological marvel, the AgentBench benchmarking tool is an indispensable tool for global entities and organizations immersed in AI development. With its aid, companies and researchers can compare the strengths and weaknesses of various language learning models, expediting development cycles, reducing costs, and fostering the creation of advanced AI systems.
Undeniably, the AgentBench benchmarking tool ushers in a new era of technological innovation. As it reshapes how AI developers approach language learning model design, development, and enhancement, it sets the stage for progress and sets new standards in the AI industry.
Empowering Precision: LLM Benchmarking
Whether you’ve engineered a pioneering language learning model or a sophisticated chatbot, Agent Bench offers unparalleled precision in evaluation. The integration of a GPU cluster further accelerates and streamlines the assessment process.
The Open LLM Leaderboard stands as a democratizing force in AI technology. It provides developers with a platform to assess their models’ performance across diverse tests. Collaborating with Eleuther AI Language Model Evaluation Harness ensures rigorous and unbiased evaluations for technologies that often defy straightforward grading.
What sets the Open LLM Leaderboard apart is its capacity to expedite department-agnostic assessments of open LLMs and chatbots. This could translate to prompt feedback, swifter iterations, refined models and, ultimately, a more seamless integration of AI into daily life.
The LLM Leaderboard has cemented its status as an integral player in the AI technology and software industry. It introduces new benchmarks and comprehensive evaluation metrics, empowering developers to glean insights and refine the performance of their language models and chatbots.
Conclusion:
Agent Bench and the Open LLM Leaderboard are ushering in a new era of AI assessment. With transparent evaluations, rigorous benchmarks, and invaluable insights, these tools are set to redefine the landscape of language model development. The AI market can anticipate enhanced accountability, faster innovation, and more advanced systems as a result of this revolutionary approach.