
- AI aims to solve diverse problems, including healthcare, where language models (LLMs) have shown promise.
- Current evaluations of LLMs in healthcare focus on static questions, lacking real-world clinical complexity.
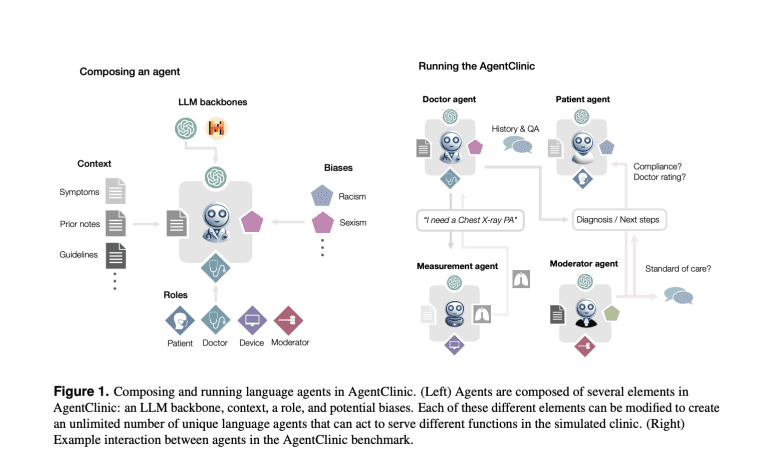
- AgentClinic, a novel benchmark, simulates clinical environments for evaluating LLMs.
- It includes patient, doctor, measurement, and moderator agents, replicating clinical interactions.
- AgentClinic integrates 24 biases and incorporates medical exams and image orders within dialogue-driven scenarios.
- GPT-4 emerged as the most accurate language model on AgentClinic-MedQA, surpassing other models.
Main AI News:
The essence of AI lies in its capacity to develop interactive solutions across various domains, notably within medical AI, dedicated to enhancing patient outcomes. Large language models (LLMs) have exhibited remarkable problem-solving prowess, even outperforming human benchmarks such as the USMLE. While LLMs hold the potential to bolster healthcare accessibility, their practical application in real-world clinical settings encounters hurdles stemming from the intricate nature of clinical tasks, which involve sequential decision-making, managing uncertainty, and delivering compassionate patient care. Present evaluation methodologies primarily center around static multiple-choice queries, inadequately capturing the dynamic essence of clinical practice.
The USMLE serves as a comprehensive assessment tool for medical students, evaluating them on foundational knowledge, clinical application, and independent practice skills. In contrast, the Objective Structured Clinical Examination (OSCE) offers a more nuanced evaluation of practical clinical competencies through simulated scenarios, facilitating direct observation and a holistic appraisal. Within the realm of medical AI, language models are predominantly scrutinized using knowledge-based benchmarks like MedQA, comprising intricate medical question-answer pairs. Recent endeavors have been directed towards refining the applicability of language models in healthcare by means of red teaming exercises and the formulation of novel benchmarks like EquityMedQA, aimed at mitigating biases and enhancing evaluation methodologies. Furthermore, strides in clinical decision-making simulations, exemplified by initiatives like AMIE, hold promise in augmenting diagnostic precision within medical AI.
Presenting AgentClinic, a groundbreaking open-source benchmark devised by researchers from Stanford University, Johns Hopkins University, and Hospital Israelita Albert Einstein. AgentClinic stands as a simulation platform designed to replicate clinical environments utilizing language, patient, doctor, and measurement agents. Distinguishing itself from prior simulations, AgentClinic incorporates medical examinations (e.g., temperature, blood pressure) and the requisition of medical images (e.g., MRI, X-ray) within dialogue-driven scenarios. Moreover, AgentClinic integrates 24 biases inherent to clinical settings, further enriching the fidelity of the simulation.
AgentClinic introduces four specialized language agents: patient, doctor, measurement, and moderator. Each agent assumes distinct roles and possesses unique data to facilitate the emulation of clinical interactions. The patient agent furnishes symptom information devoid of diagnostic knowledge, while the measurement agent dispenses medical readings and test outcomes. The doctor agent, tasked with patient evaluation and test requisition, collaborates with the moderator, responsible for scrutinizing the doctor’s diagnosis. Leveraging curated medical inquiries sourced from the USMLE and NEJM case challenges, AgentClinic crafts structured scenarios tailored for evaluation employing language models such as GPT-4.
The efficacy of various language models, including GPT-4, Mixtral-8x7B, GPT-3.5, and Llama 2 70B-chat, is assessed on AgentClinic-MedQA, wherein each model assumes the role of a doctor agent diagnosing patients via dialogue. Notably, GPT-4 emerges as the top performer with an accuracy rate of 52%, trailed by GPT-3.5 at 38%, Mixtral-8x7B at 37%, and Llama 2 70B-chat at 9%. Comparative analysis with MedQA accuracy underscores the limited predictability of AgentClinic-MedQA accuracy, mirroring findings from studies on the performance of medical residents vis-à-vis the USMLE.
Conclusion:
AgentClinic represents a significant advancement in evaluating language models for healthcare applications. Its introduction of dynamic clinical simulations, integration of biases, and comprehensive assessment approach address critical limitations in current evaluation methodologies. For the market, this signifies a pivotal step towards enhancing the reliability and applicability of language models in real-world clinical settings, potentially fostering greater adoption and innovation in AI-driven healthcare solutions.