
TL;DR:
- Google AI compares RLAIF and RLHF for language model training.
- RLAIF uses pre-trained LLM for preferences, bypassing human annotators.
- Summarization tasks are the focus of this study.
- Both RLAIF and RLHF outperform SFT in preference rankings.
- RLAIF and RLHF achieve near-equal preference ratings in direct human comparisons.
- RLAIF emerges as a viable alternative to RLHF, offering autonomy and scalability.
- Study suggests potential applications beyond summarization tasks.
- Cost-effectiveness of LLM inference vs. human labeling remains unexplored.
Main AI News:
In the realm of machine learning, the critical role of human feedback in refining and optimizing models cannot be overstated. Recent years have witnessed the ascendancy of Reinforcement Learning from Human Feedback (RLHF) as a potent tool for aligning Large Language Models (LLMs) with human preferences. However, the formidable hurdle of amassing high-quality human preference labels looms large. Google AI’s research endeavor embarks on a path to compare RLHF with Reinforcement Learning from AI Feedback (RLAIF). RLAIF, a technique in which preferences are discerned by a pre-trained LLM rather than relying on human annotators, emerges as a compelling alternative.
In a comprehensive study, Google AI’s researchers ventured to directly juxtapose RLAIF and RLHF, focusing on the domain of summarization tasks. The task involved furnishing preference labels for two prospective responses, all while leveraging an off-the-shelf Large Language Model (LLM). Subsequently, a reward model (RM) was meticulously crafted based on preferences elucidated by the LLM, augmented by a judiciously employed contrastive loss function. The culmination of this intricate process involved the fine-tuning of a policy model through advanced reinforcement learning techniques.
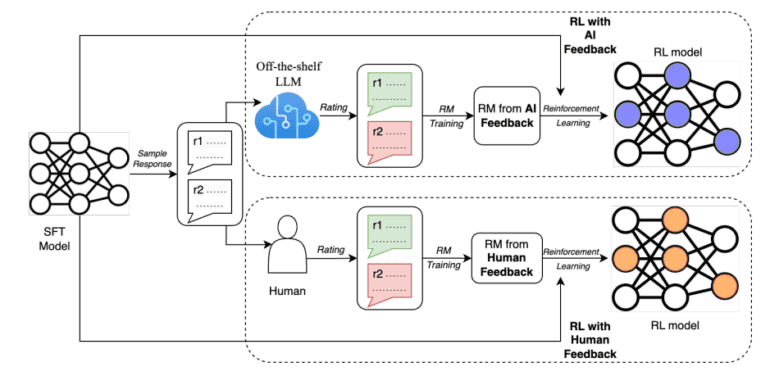
A visual representation, as depicted in the accompanying diagram, delineates the dichotomy between RLAIF (top) and RLHF (bottom), underscoring the innovative approach RLAIF brings to the table.
The study’s findings are nothing short of remarkable. In the realm of summarization, RLAIF and RLHF have demonstrably outperformed Supervised Fine-Tuning (SFT), a baseline model notorious for its failure to encapsulate critical nuances.
The presented results unveil the formidable prowess of RLAIF, positioning it as a worthy contender to RLHF. A meticulous evaluation conducted along two distinct dimensions has yielded compelling insights:
- Preference from Human Evaluators: Both RLAIF and RLHF policies garnered preference over the supervised fine-tuned (SFT) baseline in a remarkable 71% and 73% of cases, respectively. Crucially, a rigorous statistical analysis has failed to unveil any significant differences in the win rates between these two approaches.
- Human Comparative Evaluation: When humans were tasked with directly comparing the output of RLAIF and RLHF, an intriguing revelation surfaced – an equal preference was expressed for both. This parity resulted in a 50% win rate for each method. This discovery signifies that RLAIF stands as a viable alternative to RLHF, operating autonomously without the need for human annotation. Moreover, RLAIF exhibits an enticing scalability profile.
While the study’s merits shine brightly, it is worth noting its scope, which primarily delves into the domain of summarization. The question of its applicability to broader tasks remains an open frontier. Additionally, the study refrains from delving into the realm of monetary considerations, leaving the question of cost-effectiveness concerning Large Language Model (LLM) inference versus human labeling for future exploration. In the coming years, researchers harbor aspirations to venture further into this intriguing territory.
Conclusion:
The emergence of RLAIF as a potent alternative to RLHF in language model training signifies a pivotal shift in the AI landscape. This innovation holds promise for enhanced autonomy and scalability, potentially impacting various industries by reducing the reliance on human annotation. While its application in summarization tasks is promising, the broader implications across diverse domains await further exploration. Additionally, the uncharted territory of cost-effectiveness between LLM inference and human labeling presents intriguing opportunities for future research and market adaptation.