
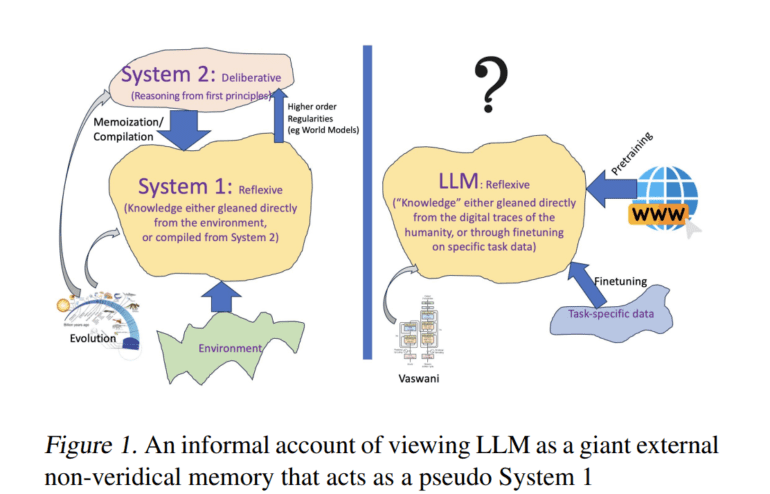
- LLMs represent a groundbreaking advancement in AI, leveraging vast textual data to exhibit impressive language generation and text completion abilities.
- They operate akin to expansive non-veridical repositories, reconstructing text prompts probabilistically rather than relying on precise data indexing.
- Questions persist regarding LLMs’ ability to engage in reasoning and planning, which are typically associated with higher-order cognitive processes.
- Research indicates inconsistent outcomes in evaluating LLMs’ cognitive capabilities, with varying levels of progress observed in tasks such as plan generation.
- Strategies to enhance LLMs’ planning abilities include fine-tuning on planning problems and providing iterative cues or recommendations.
- Employing an external model-based plan verifier could establish a robust framework for validating solution accuracy.
Main AI News:
Large Language Models (LLMs) stand as a recent and remarkable innovation within the realm of Artificial Intelligence (AI). Drawing from vast reservoirs of textual data sourced from the Internet, these supercharged n-gram models have encapsulated a significant breadth of human knowledge. The prowess exhibited by these models in language generation and text completion, portraying nuanced linguistic behaviors within completion systems, has left many astounded.
Conceptualizing LLMs as expansive, non-veridical repositories akin to external cognitive apparatuses for humanity proves beneficial in grasping their essence. Unlike conventional databases that rely on precise data indexing and retrieval mechanisms, LLMs operate more probabilistically, facilitating word-by-word reconstructions of text prompts. This method, termed approximation retrieval, enables LLMs to craft distinct completions based on received inputs, diverging from conventional memorization paradigms.
Questions arise concerning the extent to which LLMs can transcend language production to engage in cognitive activities such as reasoning and planning, often associated with higher-order cognitive functions. Unlike human beings or traditional AI systems, LLMs lack inherent predispositions towards principled reasoning, eschewing complex computational inference and search processes during both training and operation.
Recent research endeavors have delved into the realm of LLMs’ capacity for reasoning and planning. The inquiry into whether LLMs genuinely possess the ability to reason from fundamental principles or merely replicate reasoning through pattern recollection assumes paramount importance. Distinguishing between pattern recognition and logical problem-solving becomes increasingly challenging as LLMs undergo training on extensive question repositories.
The outcomes of endeavors aimed at evaluating LLMs’ cognitive capabilities have yielded varied results. Initial assessments on planning tasks, including those derived from the International Planning Competition, have contradicted anecdotal claims regarding LLMs’ planning proficiencies. Subsequent investigations utilizing updated LLM iterations, such as GPT-3.5 and GPT-4, have demonstrated incremental progress in plan generation, albeit with discrepancies in accuracy across different domains.
Researchers have proposed strategies to enhance LLMs’ planning prowess, including fine-tuning on planning problems to refine prediction accuracy. However, such approaches tend to transform planning tasks into exercises centered on memory-based retrieval rather than genuine planning activities. Alternatively, providing LLMs with cues or recommendations to iteratively refine their initial plan predictions presents another avenue for improvement, albeit with concerns regarding answer certification and the efficacy of manual versus automated prompting.
A preferable approach involves employing an external model-based plan verifier to activate LLMs and validate solution accuracy, thereby establishing a robust generate-test-critique framework. Conversely, over-reliance on human intervention risks engendering the Clever Hans effect, wherein human input unduly influences LLM estimations. Doubts persist regarding LLMs’ capacity for self-improvement through iterative self-critique, given the absence of conclusive evidence supporting their proficiency in solution validation relative to solution generation.
Conclusion:
The evolving understanding of LLMs’ cognitive capacities underscores the need for businesses to discern between their language production capabilities and their proficiency in higher-order cognitive tasks like reasoning and planning. While advancements are being made, uncertainties remain regarding their reliability in complex problem-solving scenarios, suggesting caution in overreliance on LLMs for critical decision-making processes within the market.