
TL;DR:
- AI2 introduces Dolma, a 3 trillion token corpus for language model research.
- Dolma addresses transparency issues in the field, offering openness and collaboration.
- Dataset includes web content, academic literature, code, fostering independent model optimization.
- Foundational principles: openness, representativeness, reproducibility, risk mitigation.
- Dolma’s data processing pipeline refines raw data into unembellished text documents.
- Dolma sets a precedent for transparency and collaborative progress in language model research.
Main AI News:
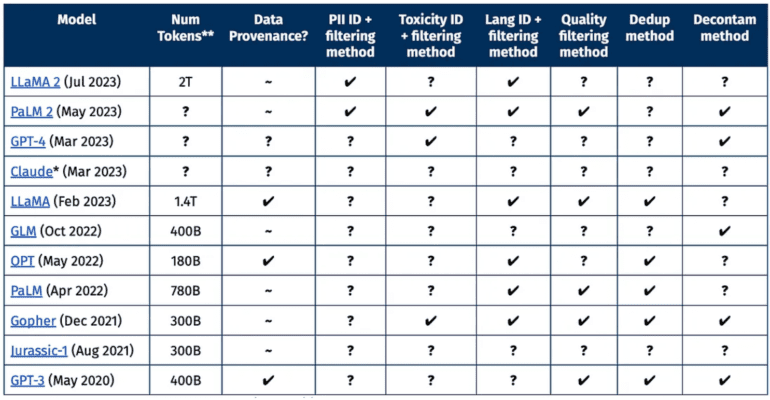
In the dynamic realm of language model advancement, issues surrounding transparency and openness have persistently cast shadows of doubt. Closed-off datasets, concealed methodologies, and limited oversight have hindered the field’s progress. Recognizing these challenges and seeking to drive transformative change, the Allen Institute for AI (AI2) has introduced an extraordinary innovation – the Dolma dataset, an expansive corpus boasting an astonishing 3 trillion tokens. The mission? To inaugurate a novel era of collaboration, transparency, and shared advancement in the arena of language model research.
Amidst the ever-evolving landscape of language model evolution, ambiguities surrounding datasets and methodologies employed by industry juggernauts like OpenAI and Meta have raised concerns. This lack of clarity not only impedes external researchers’ ability to meticulously analyze, replicate, and refine existing models but also stifles the overarching growth of the field. Enter Dolma, AI2’s brainchild, emerging as a beacon of transparency in a landscape clouded by secrecy. Anchored by an all-encompassing dataset spanning web content, academic literature, code repositories, and more, Dolma empowers the research community with the essential resources to construct, deconstruct, and optimize language models independently.
At the heart of Dolma’s genesis are foundational principles that shape its very essence. Foremost among them is the principle of openness – a principle championed by AI2 to dismantle barriers linked to restricted access to pretraining corpora. This guiding philosophy fosters the creation of enhanced iterations of the dataset and encourages an in-depth examination of the intricate relationship between data and the foundational models it supports.
Moreover, Dolma’s design underscores the importance of representativeness, mirroring established language model datasets to ensure comparable capabilities and behaviors. The dataset’s scale is also a critical consideration, as AI2 delves into the dynamic interplay between model dimensions and dataset sizes. This approach is further bolstered by principles of reproducibility and risk mitigation, upheld by transparent methodologies and a steadfast commitment to minimizing potential harm to individuals.
The inception of Dolma entails a meticulous data processing journey. Encompassing source-specific and source-agnostic operations, this pipeline meticulously transforms raw data into refined, unembellished textual documents. This intricate process involves multifaceted tasks, including language identification, curation of web data from the Common Crawl, quality filters, deduplication procedures, and strategies to mitigate risks. By incorporating code subsets and drawing from diverse sources – ranging from scientific manuscripts to Wikipedia and Project Gutenberg – Dolma achieves an unparalleled level of comprehensiveness.
Conclusion:
In the ever-evolving language model landscape, AI2’s introduction of the Dolma dataset marks a significant shift towards transparency and collaboration. Dolma’s expansive corpus and foundational principles signal a new era of research accessibility and advancement. This move holds the potential for reshaping the language model market, driving innovation through shared knowledge and fostering a responsible approach to AI development.