
- Amazon introduces BASE TTS, a groundbreaking Text-to-Speech (TTS) model.
- BASE TTS stands for Big Adaptive Streamable TTS with Emergent Abilities.
- It leverages large language models (LLMs) and transformer-based architectures.
- Trained on 100K hours of speech data, BASE TTS captures complex probability distributions for expressive speech.
- Introduces speaker-disentangled speech codes for improved phonemic and prosodic information.
- This represents a significant leap forward in TTS technology, setting new benchmarks for speech synthesis.
Main AI News:
In the ever-evolving landscape of technology, groundbreaking innovations continually redefine our expectations. Amazon’s latest venture into machine learning research introduces BASE TTS, a pioneering Text-to-Speech (TTS) model heralding a new era in speech processing. BASE TTS, an acronym for Big Adaptive Streamable TTS with Emergent Abilities, represents a significant leap forward in the realm of speech synthesis.
Recent years have witnessed a seismic shift in the approach to deep learning models, with a move away from specialized, supervised systems towards more generalized models capable of multifaceted tasks with minimal guidance. This evolution has propelled advancements not only in Natural Language Processing (NLP) and Computer Vision (CV) but also in Speech Processing and TTS.
The driving force behind this transformation lies in the advent of large language models (LLMs) and transformer-based architectures, which have enabled the processing of vast datasets, leading to unprecedented levels of performance. Amazon’s BASE TTS exemplifies this progress, drawing on approximately 100K hours of public domain speech data to train a large TTS (LTTS) system.
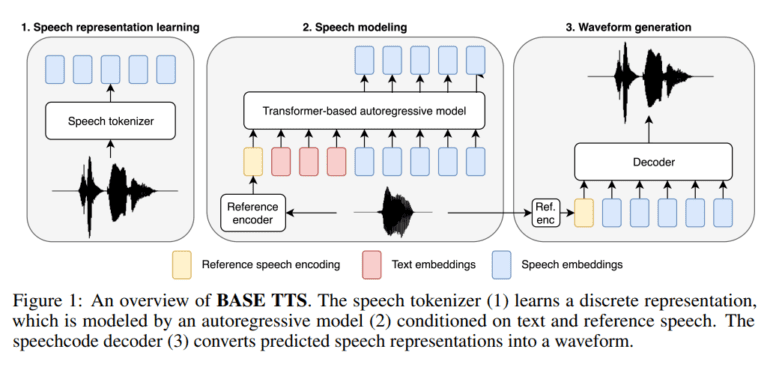
At its core, BASE TTS is designed to model the intricate relationship between text tokens and discrete speech representations, known as speech codes. By harnessing the power of decoder-only autoregressive Transformers, BASE TTS achieves a level of sophistication that significantly surpasses early neural TTS systems. This advancement enables the model to capture complex probability distributions of expressive speech, resulting in a remarkable improvement in prosody rendering.
Moreover, researchers at Amazon AGI have pioneered speaker-disentangled speech codes, a novel approach that aims to isolate phonemic and prosodic information. These codes, built on a foundation of WavLM Self-Supervised Learning (SSL) speech models, outperform conventional quantization methods and enable the generation of high-quality waveforms with unparalleled efficiency.
The implications of these advancements are profound, signaling a paradigm shift in the field of TTS. By introducing BASE TTS, the largest TTS model to date, Amazon demonstrates the transformative potential of scaling models to larger datasets and sizes. Furthermore, the introduction of novel discrete speech representations sets a new standard for speech synthesis technology, paving the way for future innovations and advancements.
Conclusion:
The introduction of Amazon’s BASE TTS marks a significant milestone in the speech technology market. By leveraging large language models and innovative transformer-based architectures, BASE TTS sets a new standard for speech synthesis. Its ability to improve prosody rendering and generate high-quality waveforms efficiently signifies a transformative shift in the industry. This innovation not only enhances the user experience but also opens doors for further advancements and competition in the market.