
TL;DR:
- aMUSEd is a revolutionary text-to-image generation model.
- Developed by Hugging Face and Stability AI, it’s a lightweight adaptation of the MUSE framework.
- aMUSEd boasts a significantly reduced parameter count, enhancing image generation speed without compromising quality.
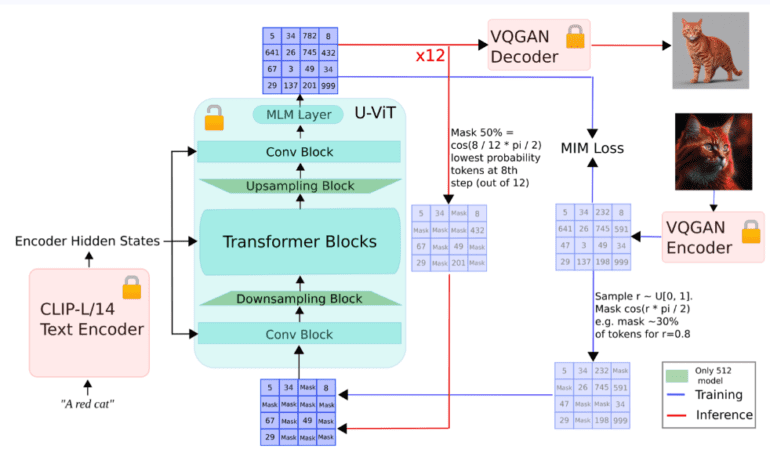
- Its unique architecture integrates a CLIP-L/14 text encoder and a U-ViT backbone, eliminating the need for a super-resolution model.
- The model can generate images at resolutions of 256×256 and 512×512, showcasing its versatility.
- aMUSEd’s inference speed is impressive, making it suitable for real-time applications.
- It excels in zero-shot in-painting and single-image style transfer tasks.
- The model’s potential lies in resource-constrained environments and quick visual prototyping.
Main AI News:
In the dynamic landscape of artificial intelligence, the convergence of language and visuals has created a unique field known as text-to-image generation. This technology holds the potential to transform textual descriptions into vivid images, bridging the gap between linguistic understanding and creative visual representation. As this field continues to evolve, it faces a significant challenge: efficiently producing high-quality images from textual prompts. This challenge extends beyond mere speed and touches upon the critical issue of computational resource utilization, ultimately affecting the practicality of such innovations.
Traditionally, text-to-image generation heavily relied on models such as latent diffusion, which employ iterative noise reduction techniques in a reverse diffusion process. While these models have achieved remarkable levels of detail and accuracy in image generation, they have come at a cost – substantial computational demands and limited interpretability. Researchers have been actively exploring alternative approaches that strike a balance between efficiency and image quality.
Enter aMUSEd, a groundbreaking solution developed by a collaborative team at Hugging Face and Stability AI. This innovative model represents a streamlined adaptation of the MUSE framework, designed for lightweight yet effective performance. What sets aMUSEd apart is its remarkable reduction in parameter count, standing at a mere 10% of MUSE’s parameters. This intentional reduction aims to significantly enhance image generation speed without compromising the output quality.
At the heart of aMUSEd’s methodology lies its distinctive architectural choices. It integrates a CLIP-L/14 text encoder and employs a U-ViT backbone, eliminating the need for a super-resolution model, a common requirement in many high-resolution image generation processes. This strategic approach simplifies the model structure and reduces the computational load, making aMUSEd an accessible tool for various applications. The model is proficient in generating images directly at resolutions of 256×256 and 512×512, showcasing its ability to produce detailed visuals without demanding extensive computational resources.
In terms of performance, aMUSEd sets new industry standards. Its inference speed surpasses that of non-distilled diffusion models and is comparable to some of the few-step distilled diffusion models. This rapid execution is essential for real-time applications, affirming the model’s practicality. Furthermore, aMUSEd excels in tasks like zero-shot in-painting and single-image style transfer, demonstrating its versatility and adaptability. In rigorous tests, the model has exhibited exceptional competence in generating less detailed images, such as landscapes, indicating its potential for applications in virtual environment design and rapid visual prototyping.
The emergence of aMUSEd represents a remarkable advancement in the realm of image generation from text. By addressing the critical challenge of computational efficiency, this technology paves the way for broader applications in resource-constrained environments. Its capacity to uphold image quality while substantially reducing computational requirements positions it as a model that could inspire future research and development. As we progress, pioneering technologies like aMUSEd have the potential to redefine the boundaries of creativity, seamlessly intertwining the worlds of language and imagery in unprecedented ways.
Conclusion:
aMUSEd’s introduction signifies a game-changing advancement in the text-to-image generation market. Its ability to combine efficiency with high-quality output opens up diverse applications, potentially reshaping the industry by making image generation more accessible and practical for a wider range of businesses and creative ventures.