
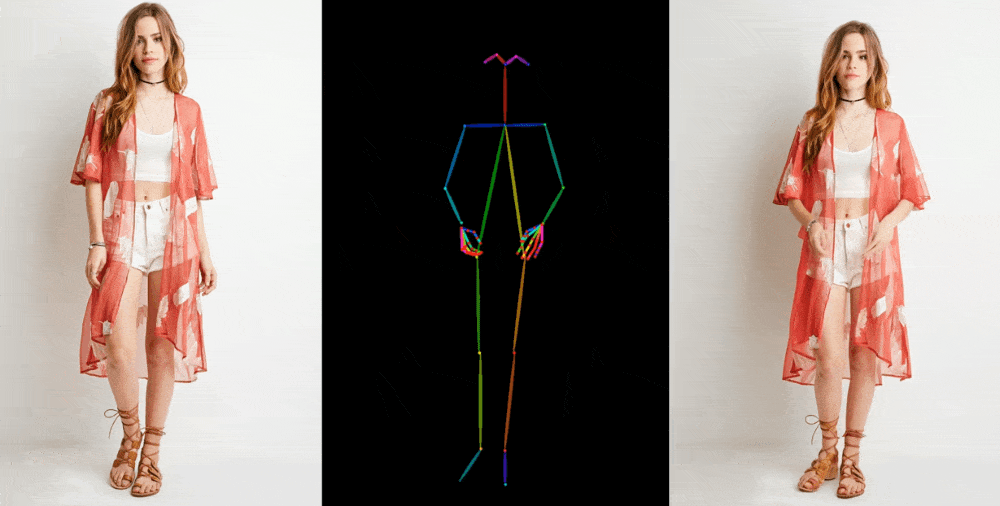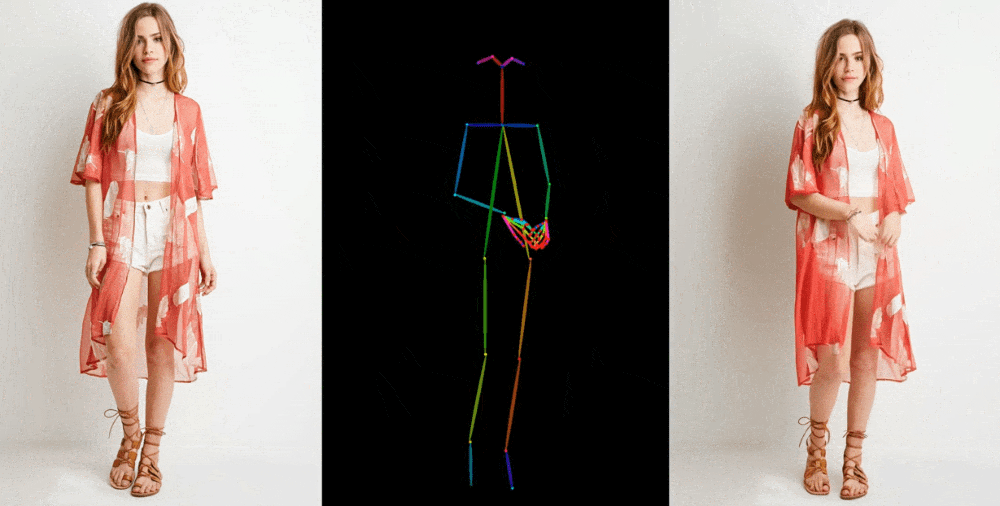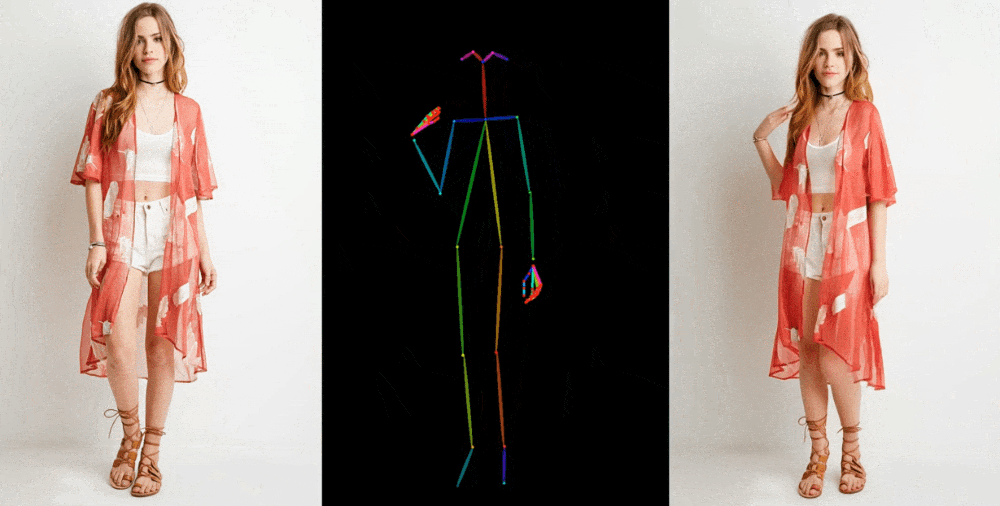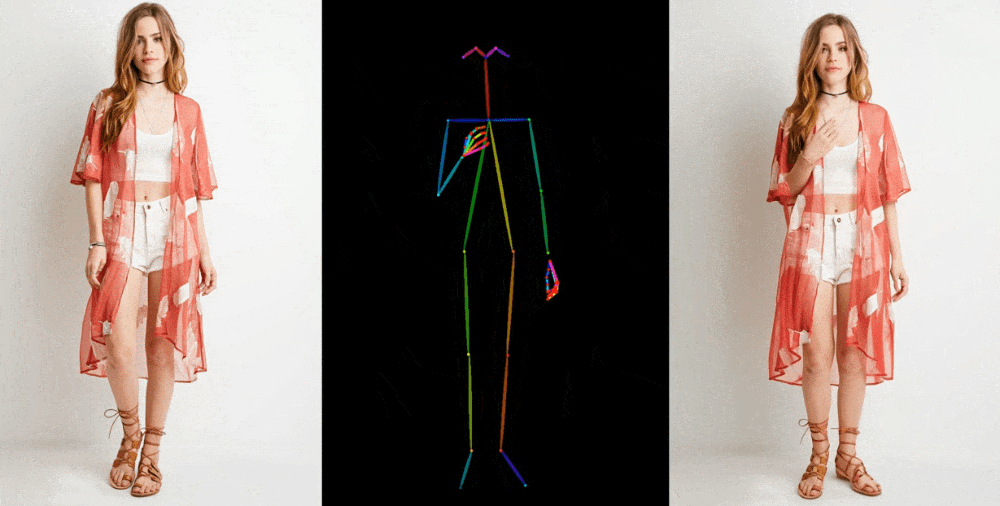
TL;DR:
- Animate Anyone, developed by Alibaba Group’s Institute for Intelligent Computing, introduces full-motion deepfakes.
- It surpasses previous image-to-video systems, like DisCo and DreamPose, in terms of realism and precision.
- The technology blurs the line between reality and fiction, challenging our perception of authenticity.
- The model extracts facial features and patterns from a reference image, generating a sequence of images with slight pose variations.
- Earlier models struggled with hallucination, producing bizarre and unconvincing results, but Animate Anyone represents a substantial improvement.
- An intermediate step enhances the preservation of appearance details, resulting in superior output.
- Demonstrations include fashion models in diverse poses, a lifelike 2D anime character, and even generic movements by Lionel Messi.
- Imperfections persist, particularly in the eyes and hands, and the model excels with poses similar to the reference image.
- The potential for misuse is concerning, as a single high-quality image can be used to manipulate individuals.
- The development team is working on preparing a public release but has not set a specific date.
- The impact of this technology on the market is uncertain but potentially disruptive.
Main AI News:
As if the realm of still-image deepfakes didn’t raise enough concerns, the horizon now unveils a new wave of technological advancement in the form of full-motion deepfakes, ushering in a new era of digital impersonation. With “Animate Anyone,” a groundbreaking generative video technique, malevolent actors can now manipulate individuals with unprecedented precision and realism.
This innovative technology is the brainchild of researchers at Alibaba Group’s Institute for Intelligent Computing. It represents a substantial leap forward from earlier image-to-video systems, such as DisCo and DreamPose, which once held our fascination but have since been relegated to the annals of history.
The capabilities of Animate Anyone, though not entirely novel, have transcended the boundaries of what was once dismissed as mere “janky academic experimentation.” It has now entered the realm of being “good enough” that people may no longer scrutinize its authenticity. Just as still images and text conversations have already blurred the line between fact and fiction, this new development threatens to further erode our sense of reality.
Image-to-video models like Animate Anyone start by dissecting details, such as facial features, patterns, and poses, from a reference image, often a fashion photograph featuring a model in attire for sale. Subsequently, a sequence of images is generated, featuring slight variations in poses, which can either be captured through motion capture or extracted from existing video footage.
Previous models grappled with a significant challenge – hallucination. They had to conjure plausible details, such as how a sleeve or hair might behave when a person moves, resulting in bizarre and unconvincing imagery. However, Animate Anyone represents a marked improvement, although it remains far from perfection.
While delving into the technical intricacies of this model may baffle most, it is worth noting an essential intermediate step highlighted in the research paper. This step empowers the model to comprehensively learn the relationship between the reference image and consistent feature space, significantly enhancing the preservation of appearance details. This improvement provides subsequent generated images with a more solid foundation, resulting in superior output.
The demonstrations presented by the researchers showcase a variety of contexts. Fashion models effortlessly assume arbitrary poses without distorting the clothing patterns. A 2D anime character springs to life and dances convincingly, while even Lionel Messi engages in a range of generic movements.
Nonetheless, imperfections persist, particularly concerning the eyes and hands, which pose formidable challenges for generative models. Furthermore, the model excels most when the poses closely resemble the original image; it struggles to maintain accuracy when subjects turn away. Nevertheless, this represents a significant leap forward from previous iterations of this technology, which often introduced artifacts and lost crucial details.
It is disconcerting to consider that a malicious actor, armed with a single high-quality image of an individual, could manipulate them into various actions. When coupled with facial animation and voice capture technologies, the possibilities become even more unsettling. While the current state of the technology is complex and riddled with bugs, it is crucial to recognize that the pace of advancement in the field of AI is relentless.
Fortunately, the development team is not yet releasing this potentially disruptive technology into the wild. While they maintain a presence on GitHub, they assert, “We are actively working on preparing the demo and code for public release. Although we cannot commit to a specific release date at this very moment, please be certain that the intention to provide access to both the demo and our source code is firm.”
As we stand on the precipice of this technological leap, one question looms large: What will happen when the internet is inundated with these ‘dancefakes’? Only time will tell, and it may arrive sooner than we would prefer.
Conclusion:
Animate Anyone’s advancements in deepfake technology represent a significant leap forward, blurring the boundaries between reality and fiction. While its potential for misuse is disconcerting, its impact on the market remains uncertain but could potentially disrupt various industries that rely on visual content and authenticity. It is crucial for businesses to stay vigilant and adapt to the evolving landscape of digital manipulation technologies.