
TL;DR:
- Anyscale and Nvidia have formed a strategic alliance.
- Nvidia’s AI software will integrate into Anyscale’s computing platform.
- The partnership includes open source and commercial components.
- TensorRT-LLM integration with Ray promises an 8x performance boost.
- GenAI developers can use Nvidia’s Triton Inference Server with Ray.
- Ray will integrate with Nvidia’s NeMo framework.
- Anyscale Endpoints enable easy LLM integration for developers.
- This partnership enhances performance and efficiency for GenAI.
Main AI News:
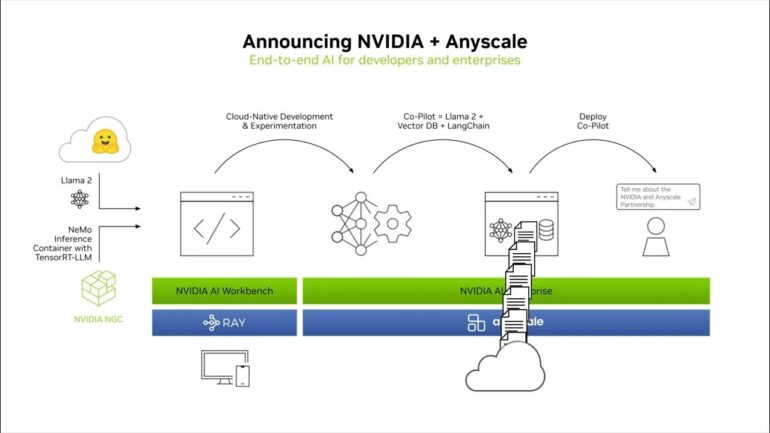
In a groundbreaking collaboration, Anyscale and Nvidia have joined forces to provide a significant boost to GenAI developers harnessing the power of large language models (LLMs). This partnership promises to seamlessly integrate Nvidia’s cutting-edge AI software into Anyscale’s versatile computing platform, opening up a world of possibilities for developers.
Anyscale, renowned as the driving force behind Ray—an open-source library born out of UC Berkeley’s RISELab—has long been at the forefront of scalable distributed applications. Their commercial offering, the Anyscale Platform, introduced in 2021, has further solidified their position as an industry leaders.
The synergy between Anyscale and Nvidia encompasses both open source and commercial facets. On the open source front, the collaboration involves the integration of several of Nvidia’s AI frameworks—TensorRT-LLM, Triton Inference Server, and NeMo—into Ray. This integration is set to revolutionize the way GenAI developers operate.
Notably, the TensorRT-LLM library’s integration with Ray promises an exceptional 8x performance boost, particularly on Nvidia’s state-of-the-art H100 Tensor Core GPUs. This leap in performance is set to redefine the boundaries of what GenAI developers can achieve.
Furthermore, developers working with Ray can now seamlessly utilize Nvidia’s Triton Inference Server when deploying AI inference workloads. This versatile server supports a wide range of processors and deployment scenarios, from cloud and edge to embedded devices. With compatibility for key frameworks like TensorFlow, PyTorch, ONNX, OpenVINO, Python, and RAPIDS XGBoost, GenAI developers gain enhanced deployment flexibility and performance.
The integration of Ray with Nvidia’s NeMo framework presents yet another milestone for GenAI applications. NeMo encompasses a myriad of components, including ML training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models. By merging these capabilities, GenAI developers stand to benefit immensely.
Not to be outdone, the alliance extends to Anyscale’s commercial offerings as well. Nvidia’s AI Enterprise software suite is set to be certified for use on the Anyscale Platform, offering a comprehensive array of tools and capabilities. This partnership also ensures seamless integration with Anyscale Endpoints—a newly introduced service designed to expedite the integration of LLMs into applications through popular APIs. This innovative solution eliminates the arduous process of custom AI platform development, providing a streamlined path to harnessing LLM superpowers.
Robert Nishihara, CEO and co-founder of Anyscale, expressed his enthusiasm for the partnership, emphasizing the enhanced performance and efficiency it brings to the Anyscale portfolio. Nishihara noted that realizing the full potential of generative AI requires computing platforms that enable developers to iterate swiftly and reduce costs in building and fine-tuning LLMs.
Conclusion:
The collaboration between Anyscale and Nvidia represents a significant advancement for the GenAI market. GenAI developers now have access to a powerful toolkit that streamlines development, enhances performance, and fosters innovation in AI applications. This strategic partnership is poised to reshape the landscape of AI development and deployment, offering new possibilities and efficiencies for businesses in the industry.