
TL;DR:
- Apple and the University of Washington unveil DATACOMP, a 12.8 billion image-text pair dataset.
- Multimodal datasets drive AI advancements in image recognition and language comprehension.
- Existing datasets lack scalability and comprehensive data-centric investigations.
- DATACOMP serves as a testbed for innovation in multimodal dataset research.
- Superior training sets lead to a 3.7% improvement in zero-shot accuracy on ImageNet.
- DATACOMP contributes to scaling trends study and enhances accessibility in multimodal learning.
Main AI News:
In the realm of artificial intelligence, the fusion of images and text data has been a game-changer, propelling advancements in image recognition, language comprehension, and cross-modal tasks. Multimodal datasets, which bring together these diverse data types, have become the cornerstone for AI model development. Researchers from Apple and the University of Washington have now introduced DATACOMP, a groundbreaking multimodal dataset testbed comprising a staggering 12.8 billion pairs of images and text data, meticulously sourced from the expansive Common Crawl.
Traditionally, researchers have strived to enhance model performance through rigorous dataset cleaning, outlier removal, and coreset selection. However, recent efforts in subset selection have focused on smaller, curated datasets, failing to account for the complexities of noisy image-text pairs and the large-scale datasets characteristic of contemporary training paradigms. Moreover, the proprietary nature of these vast multimodal datasets has posed significant challenges, limiting comprehensive data-centric investigations.
While multimodal learning has witnessed remarkable progress, notably in zero-shot classification and image generation, it has largely relied on immense datasets like CLIPs (comprising 400 million pairs) and Stable Diffusions (consisting of two billion pairs from LAION-2B). Surprisingly, these proprietary datasets have often been treated with a lack of detailed scrutiny. Enter DATACOMP, designed to bridge this knowledge gap, serving as a testbed for conducting multimodal dataset experiments.
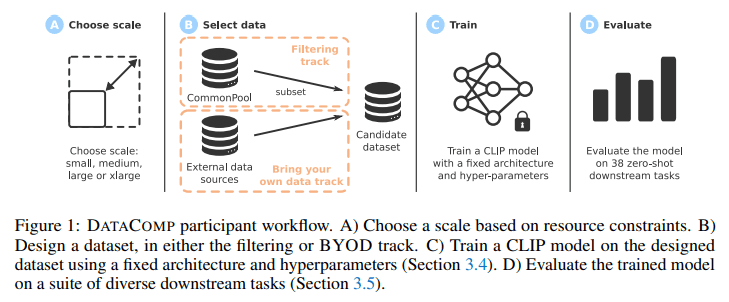
Within the DATACOMP framework, researchers are empowered to design and evaluate novel filtering techniques and data sources. They leverage standardized CLIP training code and put their innovations to the test across 38 downstream datasets. The ViT architecture, chosen for its favorable CLIP scaling trends over ResNets, forms the foundation of these experiments. In medium-scale endeavors, the ViT-B32 architecture is replaced by a ConvNeXt model. DATACOMP provides an arena for innovation and assessment in multimodal dataset research, leading to an enriched understanding and the refinement of models for superior performance.
The results speak volumes about DATACOMP’s potential. DATACOMP-1B, a product of its workflow, showcases a remarkable 3.7 percentage point improvement over OpenAI’s CLIP ViT-L/14 in zero-shot accuracy on the ImageNet dataset, achieving an impressive 79.2%. This underscores the efficacy of DATACOMP’s approach, demonstrating its applicability and promise. Furthermore, the benchmark encompasses diverse compute scales, accommodating researchers with varying resources and facilitating the study of scaling trends across four orders of magnitude. The vast image-text pair resource known as COMMONPOOL, derived from Common Crawl, is a testament to DATACOMP’s commitment to accessibility and its contribution to the evolution of multimodal learning.
Conclusion:
The introduction of DATACOMP, a massive multimodal dataset, signifies a significant leap forward in the machine learning market. Its potential to drive innovation in multimodal model development and its contribution to scaling trends study will empower researchers and enhance the capabilities of AI systems. This development reinforces the growing importance of comprehensive multimodal datasets in pushing the boundaries of AI, making DATACOMP a game-changer in the market.