
TL;DR:
- Apple researchers introduce LiDAR, a novel metric for assessing representation quality in Joint Embedding (JE) architectures.
- LiDAR distinguishes between informative and uninformative features, offering a more intuitive gauge of information content.
- It dissects complex text prompts into discrete elements and employs a tuning-free customization model for accurate representation.
- Experimental validation conducted on the Imagenet-1k dataset demonstrates LiDAR’s superiority over previous methods like RankMe.
- LiDAR showcases significant improvement in compositional text-to-image generation, highlighting its efficacy in addressing complex object representation challenges.
Main AI News:
The realm of self-supervised learning (SSL) stands as an indispensable cornerstone in the landscape of artificial intelligence, particularly in the realm of pretraining representations across expansive, unlabeled datasets. This approach substantially mitigates the reliance on annotated data, a persistent bottleneck in the realm of machine learning. However, amidst its merits, a formidable challenge persists within SSL, notably in Joint Embedding (JE) architectures—the assessment of representation quality sans dependency on downstream tasks and annotated datasets. This evaluation serves as a pivotal cog in the optimization of architecture and training strategies, yet is often impeded by inscrutable loss curves.
Traditionally, SSL models are evaluated based on their efficacy in downstream tasks, necessitating substantial resource allocation. Recent advancements have leaned towards statistical estimators grounded in empirical covariance matrices, such as RankMe, to gauge representation quality. However, these methodologies exhibit constraints, particularly in discerning between informative and uninformative features.
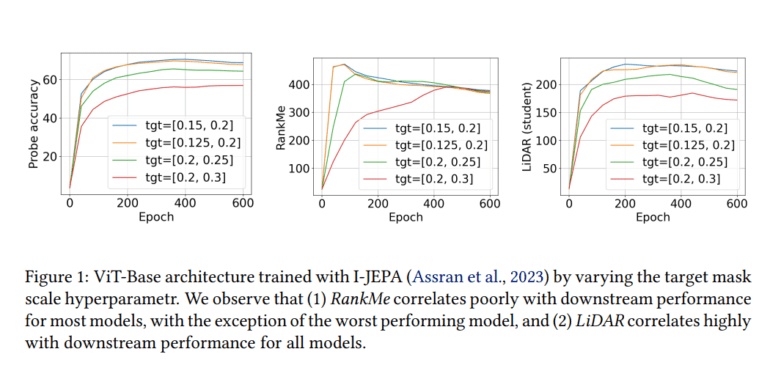
Addressing these constraints head-on, a cadre of Apple researchers has unveiled LiDAR—a novel metric poised to revolutionize the landscape. Diverging from its predecessors, LiDAR meticulously distinguishes between informative and uninformative features within JE architectures. It delineates the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task, thereby furnishing a more intuitive gauge of information content.
LiDAR embarks on its journey by dissecting complex text prompts into discrete elements, processing them autonomously. Leveraging a tuning-free multi-concept customization model alongside a layout-to-image generation model, ensures a precise representation of objects and their attributes. Experimental endeavors unfold against the backdrop of the Imagenet-1k dataset, with the train split serving as the source dataset for pretraining and linear probing, while the test split assumes the mantle of the target dataset.
Researchers cast their investigative net wide, encompassing five distinct multiview JE SSL methodologies—namely I-JEPA, data2vec, SimCLR, DINO, and VICReg—as archetypal representatives for evaluation. To scrutinize the efficacy of RankMe and LiDAR on previously unseen or out-of-distribution (OOD) datasets, CIFAR10, CIFAR100, EuroSAT, Food101, and SUN397 datasets were enlisted. LiDAR emerges triumphant, eclipsing antecedent methodologies like RankMe in predictive prowess concerning optimal hyperparameters. It showcases a noteworthy improvement of over 10% in compositional text-to-image generation, underscoring its efficacy in navigating the labyrinthine challenges of complex object representation in image generation.
Amidst the accolades, it behooves stakeholders to reckon with certain limitations intrinsic to LiDAR. Instances arise where the LiDAR metric demonstrates a negative correlation with probe accuracy, particularly in scenarios grappling with higher dimensional embeddings. This nuances the intricate interplay between rank and downstream task performance, elucidating that a lofty rank doesn’t invariably herald superior performance.
Conclusion:
Apple’s introduction of LiDAR signifies a significant leap in the evaluation paradigm for Joint Embedding architectures. Its ability to discern between informative and uninformative features, coupled with superior performance in experimental validation, heralds a promising future for more nuanced and accurate representation quality assessment in the AI market. This innovation is poised to drive advancements in various AI applications, particularly in image generation and object representation tasks.