
TL;DR:
- Astraios is a collection of 28 instruction-tuned Code LLMs.
- These models cover a wide range of tasks in software engineering.
- Models are fine-tuned using seven methods and vary in size from 1B to 16B parameters.
- PEFT configurations and methods are integrated to enhance performance.
- The primary evaluation focuses on five code-related tasks and model robustness.
- Larger models excel in code generation but raise concerns about security.
- The study establishes a correlation between model loss and task performance.
- Consistency in relative loss performance across model sizes is observed.
Main AI News:
In the ever-evolving landscape of artificial intelligence, the emergence of Large Language Models (LLMs) trained on Code has revolutionized software engineering tasks. These remarkable models can be categorized into three distinct paradigms: (i) Code LLMs specializing in code completion, (ii) Task-specific Code LLMs fine-tuned for specific assignments, and (iii) Instruction-tuned Code LLMs, which excel in adhering to human instructions and showcase remarkable versatility in tackling new tasks. Notable instruction-tuned Code LLMs like WizardCoder and OctoCoder have consistently demonstrated cutting-edge performance across a multitude of tasks, all without the need for task-specific fine-tuning.
Taking a deep dive into these promising developments, a collaborative effort between Monash University and ServiceNow Research has given birth to ASTRAIOS. This groundbreaking collection comprises 28 instruction-tuned Code LLMs, each meticulously fine-tuned using seven different tuning methods, all based on the robust base models of StarCoder. These models come in various sizes, ranging from 1 billion to 16 billion parameters, ensuring a comprehensive enhancement of their capabilities.
To achieve this impressive feat, they leverage PEFT (Performance Enhancement through Fine-Tuning) configurations aligned with Hugging Face’s recommended practices. Furthermore, they incorporate select PEFT methods from recent frameworks, ensuring that their models are at the forefront of AI technology. The team’s initial assessment revolves around the scalability of different tuning methods, with a particular focus on evaluating model size and training time scales.
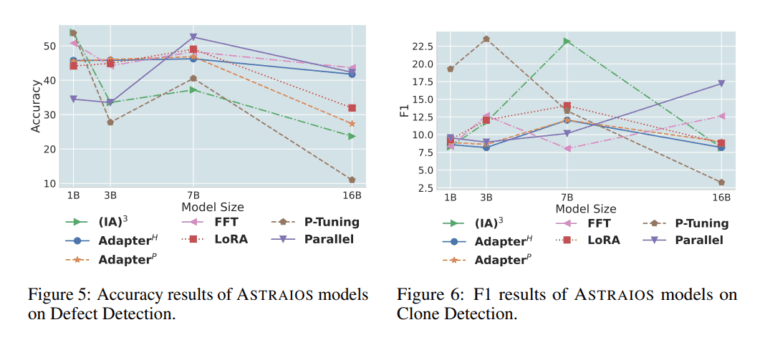
The primary evaluation of ASTRAIOS centers around five crucial code-related tasks: clone detection, defect detection, code synthesis, code repair, and code explanation. In addition to this, they conduct an in-depth analysis of the tuning methods, scrutinizing model robustness and code security. This extensive evaluation encompasses the models’ ability to generate code based on perturbed examples and identify potential vulnerabilities within the generated code.
It’s worth noting that while larger PEFT Code LLMs excel in code generation tasks, they do not exhibit similar advantages in code comprehension tasks such as clone detection and defect detection. As the model size increases, performance in code generation improves, but it also raises concerns regarding susceptibility to adversarial examples and a potential bias towards insecure code.
Their study takes a comprehensive look at the relationship between updated parameters, cross-entropy loss, and task performance. Remarkably, they find that the final loss of smaller PEFT models can reliably predict that of larger ones. Additionally, a strong correlation exists between the last loss and the overall performance in downstream tasks.
Interestingly, the correlation between model loss and updated parameters varies across different model sizes in their analysis. However, they make a significant discovery: there is a remarkable consistency in relative loss performance across various model sizes when comparing different tuning methods. This uniformity implies that the enhancements achieved by each tuning method are comparable, regardless of the model’s scale. Consequently, the loss observed in smaller models tuned using different methods can serve as a valuable indicator for predicting the performance of larger models.
Conclusion:
Astraios’ innovative AI models promise to revolutionize software engineering by offering versatile solutions for various tasks. With a focus on robustness and performance predictability, this advancement opens new opportunities for businesses seeking AI-driven software solutions, bridging the gap between code generation and comprehension tasks while ensuring security and reliability.