
TL;DR:
- Large language models (LLMs) like ChatGPT and GPT-4 have greatly advanced natural language processing in the AI community.
- However, incorporating audio modality (speech, music, sound, talking heads) into AI systems has been challenging.
- “AudioGPT” is a system developed by researchers to excel in understanding and producing audio modality in spoken dialogues.
- Audio foundation models are used instead of training multi-modal LLMs from scratch, saving computational resources.
- By connecting LLMs with input/output interfaces for speech conversations, AudioGPT tackles various audio understanding and generation tasks.
- The system leverages ChatGPT’s conversation engine and prompt manager to determine user intent during audio data processing.
- AudioGPT’s effectiveness is demonstrated in processing complex audio data for different AI applications.
- The integration of AudioGPT with ChatGPT enables efficient conversion of speech to text and facilitates rich audio material production.
- AudioGPT’s open-source code fosters collaboration and innovation in the research community.
Main AI News:
The rise of large language models (LLMs) such as ChatGPT and GPT-4 has revolutionized the AI community and propelled advancements in natural language processing. These powerful models can read, write, and converse like humans, thanks to their robust architecture and access to vast amounts of web-text data. However, while LLMs have found great success in text processing and generation, their utilization of the audio modality (including speech, music, sound, and talking heads) has been limited, despite its numerous advantages. Incorporating audio processing into AI systems is essential for achieving artificial generation success, as spoken language is integral to human communication in real-world scenarios, where individuals rely on spoken assistants to enhance convenience.
Nevertheless, training LLMs to support audio processing presents several challenges. The primary obstacles are as follows:
- Data scarcity: Obtaining real-world spoken conversations and human-labeled speech data is a costly and time-consuming endeavor. Unlike the vast corpora of web-text data, sources providing such audio data are limited. Moreover, the need for multilingual conversational speech data further compounds the challenge.
- Computational demands: Training multi-modal LLMs from scratch requires substantial computational resources and is a time-intensive process.
To address these hurdles, a collaborative team of researchers from Zhejiang University, Peking University, Carnegie Mellon University, and the Remin University of China introduces “AudioGPT” in their latest work. This system is designed to excel in comprehending and producing audio modality in spoken dialogues. The researchers adopt the following key strategies:
- Utilizing audio foundation models: Instead of training multi-modal LLMs from scratch, the team leverages a range of audio foundation models to process complex audio information effectively.
- Connecting LLMs with input/output interfaces: Rather than training a spoken language model, the researchers integrate LLMs with input/output interfaces tailored for speech conversations. This enables AudioGPT to address a wide array of audio understanding and generation tasks.
The futility of training from scratch becomes apparent when considering that audio foundation models already possess the ability to comprehend and produce speech, music, sound, and talking heads. By employing input/output interfaces, ChatGPT, and spoken language, LLMs can communicate more effectively by converting speech to text. In this process, ChatGPT’s conversation engine and prompt manager play crucial roles in determining the user’s intent when processing audio data.
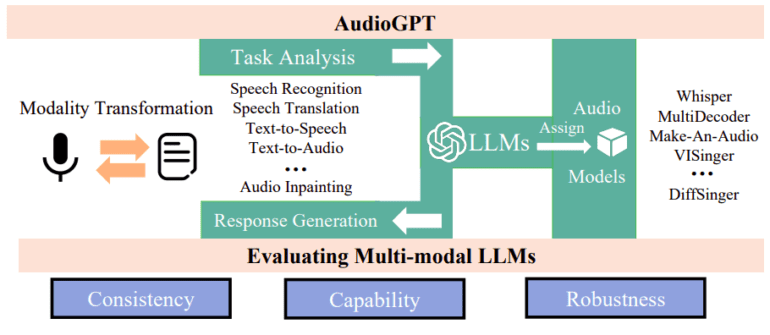
The AudioGPT process can be divided into four main parts, as depicted in Figure 1:
- Modality transformation: Leveraging input/output interfaces, ChatGPT, and spoken language, LLMs enhance communication efficacy by converting speech to text.
- Task analysis: ChatGPT utilizes its conversation engine and prompt manager to discern the user’s intent during audio data processing.
- Model allocation: ChatGPT assigns appropriate audio foundation models for comprehension and generation based on structured arguments related to prosody, timbre, and language control.
- Response design: Generating and delivering a final answer to users by executing the audio foundation models.
Assessing the effectiveness of multi-modal LLMs in comprehending human intention and orchestrating the collaboration of various foundation models has become an increasingly popular research focus. Experimental results demonstrate that AudioGPT excels at processing complex audio data in multi-round dialogues for various AI applications, including speech creation and comprehension, music generation, sound synthesis, and talking head animation. The researchers elaborate on the design concepts and evaluation procedures employed to ensure AudioGPT’s consistency, capacity, and robustness.
Conclusion:
The development of AudioGPT and its incorporation of audio foundation models signify a significant leap forward in the AI market. By addressing the limitations of previous models in understanding and generating audio content, AudioGPT opens up new opportunities for applications requiring speech, music, sound, and talking head processing. This advancement has the potential to revolutionize industries such as virtual assistants, audio content creation, and human-computer interaction. The availability of open-source code further encourages collaboration and the development of innovative audio-driven AI solutions. As businesses strive to enhance user experiences and explore the possibilities of audio modalities, AudioGPT stands as a powerful tool to drive innovation and unlock the potential of multi-modal AI systems.