
TL;DR:
- Large Language Models (LLMs) like ChatGPT and CLIP are revolutionizing human-machine interactions.
- Google introduces AudioPaLM, a unified LLM that combines text-based language models and audio prompting techniques.
- AudioPaLM excels in speech understanding and generation tasks, handling applications such as voice recognition and voice-to-text conversion.
- By leveraging the strengths of PaLM-2 and AudioLM models, AudioPaLM achieves comprehensive comprehension and creation of both text and speech.
- Its joint vocabulary and markup task descriptions enable a single decoder-only model for various voice and text-based tasks.
- AudioPaLM outperforms existing systems in speech translation, demonstrating zero-shot capabilities and voice transfer across languages.
- Key contributions include state-of-the-art results in Automatic Speech Translation and Speech-to-Speech Translation benchmarks.
Main AI News:
Large Language Models (LLMs) have been making headlines lately, representing a groundbreaking advancement in Artificial Intelligence. These models are reshaping human-machine interactions and are being adopted across various industries, exemplifying the unstoppable rise of AI. Among them, the remarkable OpenAI’s ChatGPT, based on the Transformer architecture of GPT 3.5 and GPT 4, stands as a prime example of LLM’s exceptional text generation capabilities. Additionally, models like CLIP (Contrastive Language-Image Pretraining) have emerged, enabling the generation of text based on image content.
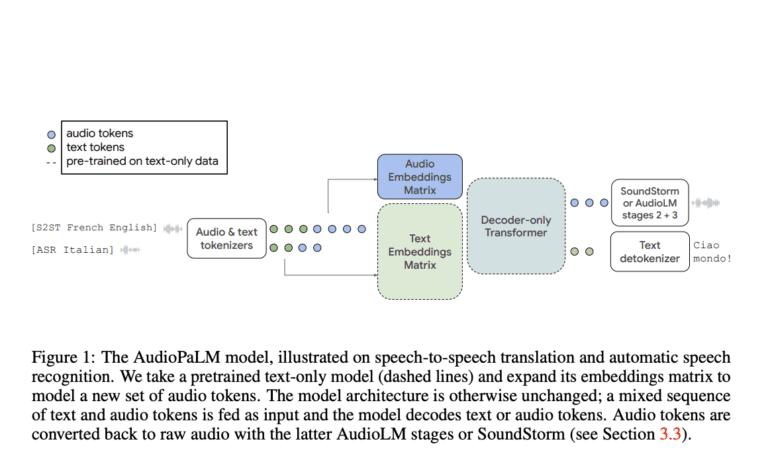
To further advance audio generation and comprehension, Google researchers have developed AudioPaLM, a game-changing large language model designed to tackle speech understanding and generation tasks. This innovative model combines the strengths of two existing models: the PaLM-2 model and the AudioLM model. By fusing their capabilities, AudioPaLM creates a unified multimodal architecture capable of processing and producing both text and speech. Its versatility enables a wide range of applications, including voice recognition and voice-to-text conversion.
AudioLM excels in preserving paralinguistic information such as speaker identity and tone. On the other hand, PaLM-2, a text-based language model, specializes in linguistic knowledge specific to the text. By harnessing the expertise of both models, AudioPaLM achieves comprehensive comprehension and creation of text and speech, ensuring a holistic approach to audio processing.
One of the remarkable features of AudioPaLM is its employment of a joint vocabulary that represents speech and text using a limited number of discrete tokens. By combining this joint vocabulary with markup task descriptions, researchers have successfully trained a single decoder-only model capable of handling diverse voice and text-based tasks. This breakthrough allows for the integration of traditionally separate models dedicated to speech recognition, text-to-speech synthesis, and speech-to-speech translation into a unified architecture and training process.
In evaluations, AudioPaLM has outperformed existing systems in speech translation by a significant margin. Its groundbreaking zero-shot speech-to-text translation ability enables the accurate transcription of speech into text for previously unencountered languages, expanding the horizons of language support. Furthermore, AudioPaLM can transfer voices across languages based on short spoken prompts, capturing and reproducing distinct voices in different languages. This breakthrough opens the doors to voice conversion and adaptation, revolutionizing the field.
The team behind AudioPaLM highlights several key contributions:
- AudioPaLM harnesses the capabilities of PaLM and PaLM-2s, derived from text-only pretraining.
- It has achieved state-of-the-art results in Automatic Speech Translation and Speech-to-Speech Translation benchmarks, while also demonstrating competitive performance in Automatic Speech Recognition benchmarks.
- The model excels in Speech-to-Speech Translation with voice transfer of previously unseen speakers, surpassing existing methods in speech quality and voice preservation.
- AudioPaLM showcases its zero-shot capabilities by performing Automatic Speech Translation with previously unseen language combinations.
Conclusion:
The introduction of AudioPaLM marks a significant milestone in the speech technology market. Its unified approach to processing both text and speech opens up new possibilities for businesses across industries. With enhanced speech understanding, accurate translation, and voice transfer capabilities, AudioPaLM provides a powerful tool for voice recognition, voice-to-text conversion, and multilingual communication. As companies seek to integrate advanced AI technologies into their operations, AudioPaLM’s exceptional performance and comprehensive language processing capabilities position it as a promising addition to the market, enabling improved customer interactions, multilingual support, and streamlined communication processes.