
TL;DR:
- Google DeepMind unveils AutoRT, a system revolutionizing autonomous robotics.
- AutoRT leverages foundation models for real-world robot adaptability.
- It addresses challenges in training robots with insufficient real-world data.
- Large language models and vision-language models enable abstract task reasoning.
- AutoRT orchestrates robot fleets through a guiding foundation model.
- Robot constitution defines rules and safety constraints for task execution.
- Key components include exploration, task generation, and affordance filtering.
- Diverse collection policies ensure data diversity, maximizing learning.
- Guardrails enhance safety in real-world settings.
Main AI News:
In a groundbreaking development, Google DeepMind has unveiled AutoRT, a cutting-edge system poised to redefine the landscape of autonomous robotics. AutoRT leverages the power of existing foundation models to empower robots to tackle unforeseen challenges, all while minimizing the need for extensive human intervention. This transformative technology addresses the perennial hurdle of training embodied foundation models for robots, a challenge rooted in the scarcity of real-world data. By harnessing vision-language models for scene comprehension and grounding and tapping into large language models to generate a diverse array of instructions, AutoRT paves the way for large-scale, real-world data collection, ultimately enabling robots to seamlessly adapt to novel environments and tasks.
Traditionally, the field of autonomous robotics has focused on honing individual robotic skills, with large language models (LLMs) and vision-language models (VLMs) offering the potential to reason over abstract tasks. However, the researchers at Google DeepMind assert that truly open-ended tasks in diverse settings present formidable obstacles, primarily due to the dearth of comprehensive real-world robotic experiences. Enter AutoRT, a visionary solution that orchestrates a fleet of robots through the guidance of a large foundation model. This model acts as the conductor, directing the robots in task execution based on user prompts, drawing from scene understanding provided by VLMs, and considering task proposals generated by LLMs, all while adhering to a meticulously crafted robot constitution that delineates rules and safety constraints.
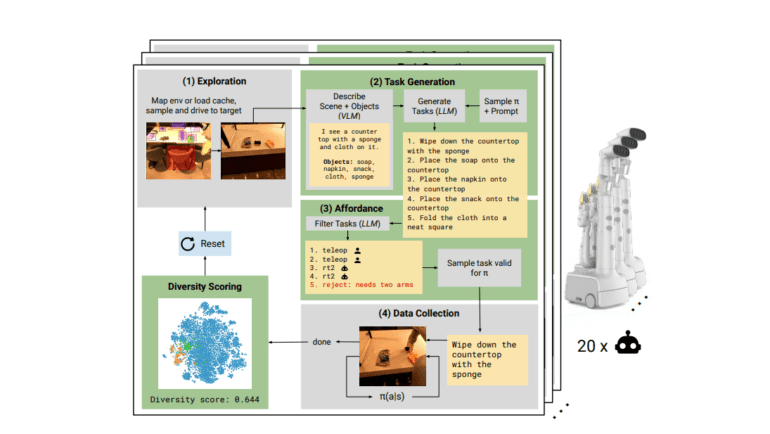
AutoRT’s innovative approach is built upon several pivotal components, each playing a crucial role in its success. The journey begins with exploration, where robots navigate and map their environment using a natural language map approach. Inspired by the principles encapsulated in Asimov’s laws, the robot constitution establishes the bedrock of foundational, safety, and embodiment rules, serving as the blueprint for the generation of tasks that prioritize both safety and efficacy. Task generation unfolds with scene descriptions crafted by VLMs and task proposals generated by LLMs, each robot receiving specific prompts tailored to its unique collection policy. Affordance filtering serves as the ultimate quality control, ensuring that generated tasks align with constitutional rules while guaranteeing their feasibility and safety. AutoRT’s quest for data diversity leads to the deployment of diverse collection policies, encompassing teleoperation, scripted pick policies, and autonomous strategies, all aimed at maximizing the richness of the collected data. To further bolster safety in real-world settings, AutoRT incorporates guardrails, which are traditional robot environment controls.
Conclusion:
AutoRT represents a revolutionary leap in the realm of autonomous robotics, heralding a new era where robots can adapt, learn, and operate in uncharted territories with unprecedented levels of autonomy. Google DeepMind’s pioneering approach, driven by AI-driven task execution, is poised to redefine the future of robotic learning, making it more versatile and capable than ever before.