
TL;DR:
- AVIS is an AI framework by UCLA and Google that uses Large Language Models (LLMs) to enhance visual information retrieval.
- AVIS integrates LLMs with various tools for dynamic decision-making in visual question answering.
- It adapts strategies on the fly, providing agility in complex real-world scenarios.
- User study data informs AVIS, replicating human decision-making processes.
- AVIS outperforms existing solutions, achieving 50.7% accuracy on Infoseek, surpassing PALI’s 16%.
- AVIS employs a range of resources, including image captioning, object detection, and web search.
- Future plans include expanding its capabilities and exploring less computationally intensive LLMs.
Main AI News:
In the rapidly evolving landscape of artificial intelligence, the intersection of visual data and question-answering has long been a challenging frontier. Traditional methods often fall short in comprehending nuanced queries and extracting specific information from images. To address these limitations, researchers from the University of California, Los Angeles (UCLA) and Google have introduced a groundbreaking solution – the Autonomous Visual Information Seeking with Large Language Models (AVIS).
The Visionary Approach of AVIS
AVIS represents a pioneering approach that harnesses the capabilities of Large Language Models (LLMs) to revolutionize the process of information retrieval from visual sources. Its primary mission is to empower AI systems with the ability to decipher complex queries, recognize relevant elements in images, and provide accurate answers. The significance of this innovation lies in its potential to bridge the gap between human-like understanding and machine-driven responses.
A Synergy of Tools and Strategies
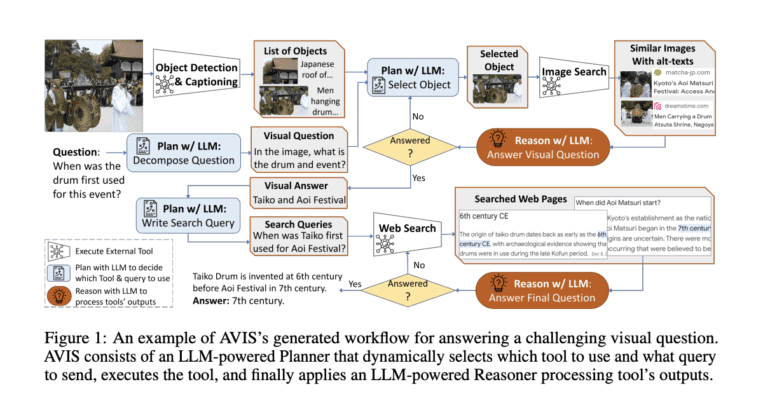
One of the key challenges in visual question answering is the need for a multifaceted approach. AVIS tackles this by seamlessly integrating LLMs with a repertoire of tools, including object detectors, optical character recognition software, image search engines, and more. This fusion of technologies enables AVIS to make informed decisions on which tool to deploy and how to formulate queries dynamically, based on the context of the task at hand.
A Dynamic Strategy for Real-World Scenarios
In contrast to static methodologies, AVIS adopts a dynamic strategy that evolves as it interacts with data. Instead of planning every step in advance, AVIS adapts on the fly, making decisions based on the evolving context. This nimbleness is a fundamental innovation that allows AVIS to handle the complexity of visual information retrieval effectively.
Learning from User Behavior
To enhance its decision-making capabilities, AVIS leverages insights from a user study. By observing how individuals interact with APIs to access visual information, AVIS builds a systematic framework that mimics human decision-making processes. This framework, in turn, guides the LLM in selecting APIs and crafting queries that align with human-like intuition.
Key Contributions of AVIS
- Innovative Framework: AVIS introduces a novel visual question-answering framework powered by LLMs, enabling dynamic tool utilization and knowledge extraction.
- Human-Inspired Decision-Making: By incorporating user study data, AVIS replicates human decision-making when selecting APIs and constructing queries.
- Superior Performance: AVIS outperforms existing solutions on Infoseek and OK-VQA benchmarks, achieving a remarkable 50.7% accuracy compared to PALI’s 16.0% on the Infoseek dataset.
The Arsenal of AVIS
AVIS arms itself with an array of resources to tackle the challenges of visual information retrieval, including:
- Image Captioning Model
- Visual Question Answering Model
- Object Detection
- Image Search
- Optical Character Recognition (OCR)
- Web Search
- LLM Short QA
Future Endeavors and Considerations
While AVIS is a significant leap forward, its developers have ambitious plans. They aim to expand their capabilities to encompass a wider range of reasoning applications. Additionally, they are exploring the feasibility of using less computationally intensive LLMs without sacrificing performance.
Conclusion:
AVIS signifies a major advancement in visual information retrieval, bridging the gap between human understanding and AI-driven responses. Its adaptability and superior performance have the potential to disrupt the market, offering more accurate and dynamic solutions for businesses and industries relying on visual data analysis. As AVIS continues to evolve, it promises to reshape the landscape of AI-driven knowledge extraction from visual sources.