
TL;DR:
- Rice University and AWS collaborate on GEMINI, a distributed training system.
- GEMINI improves failure recovery in large-scale machine learning models.
- It optimizes CPU memory for checkpoints, enhancing availability.
- Outperforms existing solutions by 13 times, reducing time wastage.
- GEMINI’s scalability and efficiency make it ideal for large-scale training.
- It addresses limitations in bandwidth and checkpoint frequency.
- It utilizes deep-speed, Amazon EC2 Auto Scaling Groups, and a smart checkpoint strategy.
Main AI News:
In a groundbreaking collaboration between Rice University and Amazon Web Services, a trailblazing distributed training system named GEMINI has emerged as a beacon of hope for enhancing failure recovery within the realm of large-scale machine learning model training. This innovative system tackles the formidable challenges associated with leveraging CPU memory for checkpoints, thereby ensuring heightened availability and minimal disruption to the training pipeline. GEMINI’s remarkable performance surpasses that of existing solutions, positioning it as a promising milestone in the field of large-scale deep-learning model training.
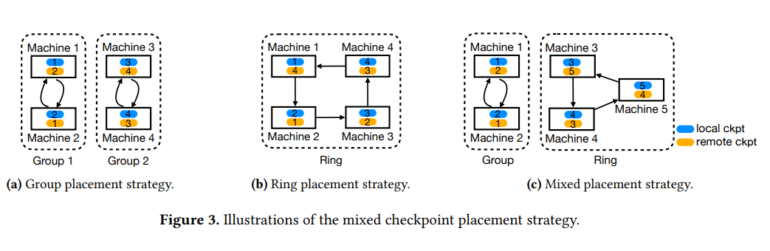
GEMINI, the brainchild of a collaboration between Rice University and Amazon Web Services, has ushered in a distributed training system that promises to revolutionize the failure recovery process in large-scale model training. In the past, bandwidth and storage limitations cast a shadow on the checkpointing frequency and model accuracy, despite the availability of checkpointing interfaces within popular deep learning frameworks such as PyTorch and TensorFlow. GEMINI takes a quantum leap by optimizing checkpoint placement and traffic scheduling, thereby staking its claim as a game-changing advancement in this domain.
The world of deep learning has marveled at the prowess of large models, yet the training of these colossal entities has been plagued by complexity and time constraints. Existing solutions for failure recovery in large model training have grappled with the shackles of limited bandwidth in remote storage, resulting in exorbitant recovery costs. Enter GEMINI, which introduces cutting-edge CPU memory techniques that facilitate swift failure recovery. Its ingenious strategies for optimal checkpoint placement and traffic scheduling have propelled it to the forefront, offering substantially faster failure recovery than its predecessors. GEMINI’s contributions to the realm of deep learning are nothing short of remarkable.
GEMINI stands on the bedrock of Deep-Speed, harnessing the power of the ZeRO-3 setting for distributed training. The management of GPU model states is entrusted to Amazon EC2 Auto Scaling Groups, while checkpoints find a home in both CPU memory and remote storage, with a frequency of every three hours. GEMINI boasts a near-optimal checkpoint placement strategy, maximizing recovery probability, and a traffic scheduling algorithm that minimizes interference. Although the evaluation is conducted on NVIDIA GPUs, its applicability extends to other accelerators like AWS Trainium.
The impact of GEMINI on failure recovery is nothing short of astounding, surpassing existing solutions by a staggering 13-fold margin. Evaluation results validate its prowess in reducing time wastage without compromising training throughput. GEMINI’s scalability is evident across a spectrum of failure frequencies and training scales, underscoring its potential for large-scale distributed training. The traffic interleaving algorithm embedded within GEMINI acts as a catalyst, further elevating the system’s efficiency.
Existing solutions for failure recovery in large model training have long grappled with the constraints of remote storage bandwidth, hampering checkpoint frequency and squandering precious time. This study delves into static and synchronous training scenarios with fixed computational resources, leaving aside considerations of elastic and asynchronous training methods. Additionally, the research does not address the issue of CPU memory size for storing checkpoint history for purposes beyond failure recovery.
Conclusion:
GEMINI’s introduction represents a significant breakthrough in the field of large-scale deep learning, offering a faster and more efficient failure recovery solution. With its impressive scalability and efficiency gains, GEMINI has the potential to reshape the market for large-scale model training, reducing costs and improving overall productivity for businesses engaged in machine learning and artificial intelligence.