
TL;DR:
- AWS introduces Amazon EC2 P5 instances powered by NVIDIA H100 Tensor Core GPUs for high-performance AI/ML and HPC workloads.
- These instances come with 8 NVIDIA H100 GPUs, 640 GB of GPU memory, 3rd Gen AMD EPYC processors, 2 TB of system memory, and 30 TB of local NVMe storage.
- P5 instances boast an aggregate network bandwidth of 3200 Gbps, enabling lower latency and efficient scale-out performance with GPUDirect RDMA.
- Training times were reduced by up to 6 times and training costs by up to 40 percent compared to previous GPU-based instances.
- Applications include Large Language Models, computer vision, pharmaceutical discovery, weather forecasting, and financial modeling.
- P5 instances are deployable in EC2 UltraClusters, functioning as robust supercomputers.
Main AI News:
In a major leap towards meeting the surging demands of high-performance computing, artificial intelligence, and machine learning workloads, Amazon Web Services (AWS) has officially rolled out the much-anticipated Amazon EC2 P5 instances. This move comes in the wake of an earlier announcement regarding the development of this cutting-edge infrastructure.
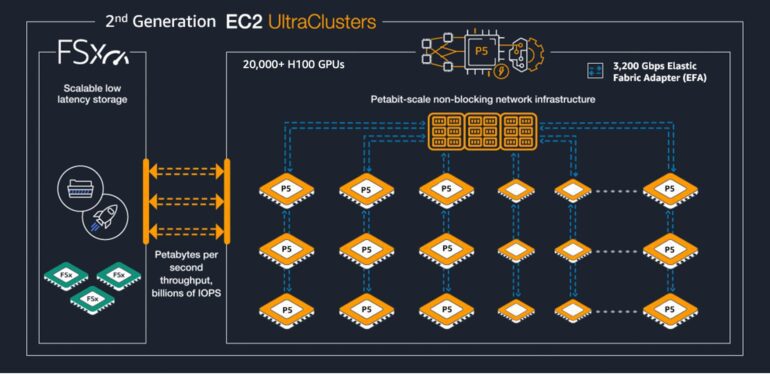
The result of a long-standing partnership between AWS and NVIDIA, the Amazon EC2 P5 instances represent the 11th iteration of instances engineered for visual computing, AI, and HPC clusters. Packed with 8 powerful NVIDIA H100 Tensor Core GPUs, boasting an impressive 640 GB of high-bandwidth GPU memory, and driven by 3rd Gen AMD EPYC processors with a staggering 2 TB of system memory, these instances are set to redefine performance benchmarks in the industry. Additionally, with a remarkable 30 TB of local NVMe storage and an aggregate network bandwidth of 3200 Gbps thanks to the second-generation Elastic Fabric Adaptor (EFA) technology, users can expect significantly lower latency and highly efficient scale-out performance through GPUDirect RDMA, effectively bypassing the CPU during internode communication.
AWS confidently claims that these instances will slash training times by up to 6 times when compared to the previous generation GPU-based instances, dramatically reducing training costs by up to 40 percent.
The Amazon EC2 P5 instances open up a world of possibilities for users, enabling them to leverage the immense power for training and running inference on increasingly intricate Large Language Models (LLMs) and computer vision models, making generative AI applications such as question answering, code generation, video and image generation, and speech recognition more attainable than ever before. Moreover, these instances are ideally suited for high-performance computing workloads, including pharmaceutical discovery, seismic analysis, weather forecasting, and financial modeling.
In an exciting development, the P5 instances are deployable within the EC2 UltraClusters, which bring together high-performance computing, advanced networking, and storage capabilities in the cloud. Each EC2 UltraCluster functions as a robust supercomputer, empowering users to execute complex AI training and distributed HPC workloads seamlessly across multiple interconnected systems.
Dave Salvator, director of accelerated computing products at NVIDIA, expressed his enthusiasm, stating, “Customers can run at-scale applications that require high levels of communications between compute nodes; the P5 instance sports petabit-scale non-blocking networks powered by AWS EFA, a 3,200 Gbps network interface for Amazon EC2 instances.”
Furthermore, Satish Bora, International GM at nOps.io, couldn’t contain his excitement, commenting on a Linked post by Jeff Barr, “It appears a small datacenter in an instance; what power.“
Notably, AWS faces stiff competition from tech giants Microsoft and Google, as they too have made significant strides in catering to AI/ML and HPC workloads. Microsoft recently unveiled Azure Managed Lustre, and AWS’s EC2 UltraClusters also harness the potential of Amazon FSx for Lustre, a fully-managed shared storage solution built on Lustre file system, an open-source parallel filesystem. Additionally, Microsoft introduced Azure HBv4 and HX Series virtual machines to optimize HPC workloads, while Google released the Compute Engine C3 machine series tailored for high-performance computing.
As of now, the Amazon EC2 P5 instances are available in the US East (N. Virginia) and US West (Oregon) regions, with pricing details accessible on the EC2 pricing page.
Conclusion:
AWS’s launch of the Amazon EC2 P5 instances signifies a significant step forward in the AI/ML and HPC market. With powerful features, reduced training times, and cost savings, businesses can achieve new levels of efficiency and productivity in complex computing tasks. The competition among cloud computing providers, including Microsoft and Google, is intensifying as they also strive to deliver high-performance solutions. The availability of P5 instances is likely to spur further innovation and demand for advanced cloud computing offerings, benefiting both AWS and the broader market.