
TL;DR:
- BiLLM revolutionizes post-training binary quantization for large language models (LLMs).
- Developed by a collaborative effort from top-tier universities, BiLLM employs advanced techniques to compress pre-trained LLMs without compromising performance.
- Leveraging weight distribution analysis and binary residual approximation, BiLLM achieves unprecedented compression while maintaining accuracy.
- The introduction of a bell-shaped distribution splitting method ensures accurate binarization of non-salient weights, further optimizing the quantization process.
- Implemented on PyTorch and Huggingface libraries, BiLLM surpasses existing methods, showcasing superior perplexity results across various model sizes and datasets.
- BiLLM’s structured approach to weight selection and optimal splitting demonstrates universality and robustness across diverse LLM settings.
Main AI News:
As the demand for high-performing language models escalates, the necessity for efficient resource utilization becomes paramount. Pretrained large language models (LLMs) exhibit unparalleled language processing capabilities but often come with hefty computational requirements. Addressing this challenge, binarization emerges as a promising solution, condensing model weights to a single bit and thereby slashing computational and memory demands.
However, the transition to binary quantization is not without its hurdles. Ensuring that LLM performance remains intact at such low bit widths poses a significant challenge. Despite the remarkable performance showcased by LLMs like OPT and LLaMA across various benchmarks, deploying them on memory-constrained devices remains a formidable task.
Enter BiLLM—a game-changing 1-bit post-training quantization method meticulously crafted for pre-trained LLMs. Developed by a collaborative effort from the University of Hong Kong, Beihang University, and ETH Zurich, BiLLM leverages advanced techniques to achieve unprecedented compression without sacrificing performance.
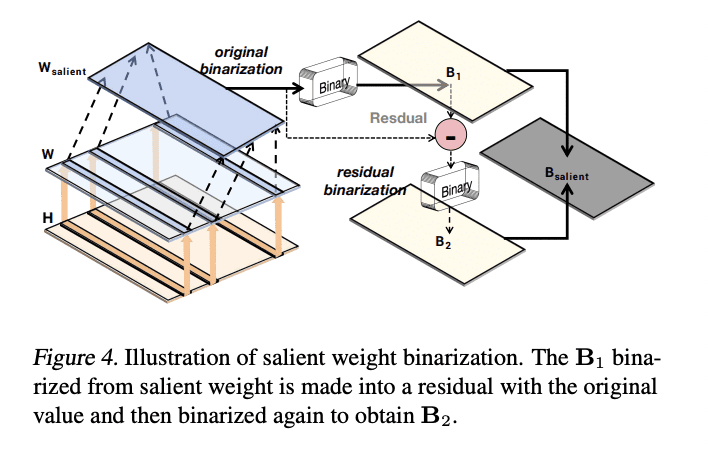
At its core, BiLLM employs weight distribution analysis to discern crucial weights and adopts a binary residual approximation strategy to mitigate compression loss effectively. Additionally, it introduces an innovative approach—a bell-shaped distribution splitting—for accurate binarization of non-salient weights, further optimizing the quantization process.
Furthermore, BiLLM leverages weight sensitivity analysis via the Hessian matrix, enabling a structured selection of salient weights and optimal splitting for non-salient ones. This meticulous approach minimizes quantization error while ensuring high-accuracy inference even at ultra-low bit widths, facilitating efficient deployment on GPUs.
Implemented on PyTorch and Huggingface libraries, BiLLM represents a significant leap forward in 1-bit post-training quantization frameworks for LLMs. Outperforming existing methods like GPTQ and PB-LLM, BiLLM showcases superior perplexity results across various model sizes and datasets, including WikiText2, PTB, and C4. Its structured binarization approach, coupled with optimal weight splitting, demonstrates unparalleled universality and robustness across diverse LLM settings.
Conclusion:
BiLLM’s groundbreaking 1-bit post-training quantization method signifies a significant advancement in the market for language model compression techniques. Its ability to compress pre-trained LLMs while preserving performance benchmarks suggests a promising future for the efficient deployment of language models across a wide array of applications and devices, ultimately driving innovation and accessibility in the field of natural language processing.