
- Large Language Models (LLMs) revolutionize text processing but pose challenges in computational and environmental costs.
- BitNet b1.58, developed by Microsoft Research and the University of Chinese Academy of Sciences, employs 1-bit ternary parameters for model weights.
- This approach significantly reduces computational resource demand while maintaining high performance levels.
- BitNet b1.58 outperforms traditional LLMs in efficiency and occasionally in performance across various tasks.
- It showcases the potential to reshape the landscape of LLM development.
Main AI News:
The evolution of Large Language Models (LLMs) has been nothing short of revolutionary, enhancing our capacity to comprehend and generate human-like text. However, with increasing size and complexity, LLMs pose substantial challenges, particularly in computational and environmental aspects. Balancing efficiency with performance has emerged as a primary focus within the AI community.
At the heart of the matter lies the substantial computational demands inherent in traditional LLMs. Their training and operational phases necessitate significant power and memory, resulting in elevated costs and environmental impact. Addressing this challenge requires exploring alternative architectures promising comparable effectiveness with reduced resource usage.
Initial attempts to mitigate the resource intensity of LLMs have centered on post-training quantization techniques. While effective in some industrial applications, these methods often entail trade-offs between efficiency and model performance.
Enter BitNet b1.58, the brainchild of a collaborative effort between Microsoft Research and the University of Chinese Academy of Sciences. BitNet b1.58 introduces a groundbreaking approach, employing 1-bit ternary parameters for every model weight. This departure from conventional 16-bit floating values to a 1.58-bit representation strikes an optimal balance between efficiency and performance.
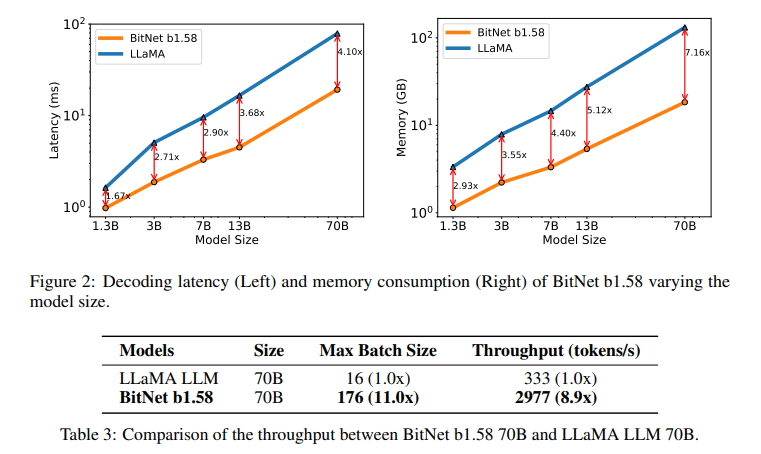
BitNet b1.58’s methodology, utilizing ternary {-1, 0, 1} parameters, significantly reduces the model’s demand on computational resources. Through intricate quantization functions and optimizations, the model maintains high-performance levels akin to full-precision LLMs while achieving notable reductions in latency, memory usage, throughput, and energy consumption.
The performance of BitNet b1.58 underscores the feasibility of achieving efficiency without compromising quality. Comparative studies demonstrate that BitNet b1.58 not only matches but occasionally surpasses conventional LLMs’ performance across diverse tasks. With faster processing speeds and lower resource consumption, BitNet b1.58 has the potential to redefine the trajectory of LLM development.
Conclusion:
The emergence of BitNet b1.58 represents a significant breakthrough in the field of Large Language Models. Its ability to achieve high efficiency without sacrificing performance has profound implications for the market. Businesses investing in AI technologies can expect improved cost-effectiveness and enhanced performance, potentially driving innovation and competitiveness within the industry. Additionally, the success of BitNet b1.58 underscores the importance of continual research and development efforts in optimizing AI technologies for broader application and impact.