
TL;DR:
- Neural radiance fields (NeRF) revolutionized how we represent and render 3D scenes, achieving impressive photorealism and detail fidelity.
- NeRF’s limitations in editing scenes stem from its implicit nature and the lack of explicit separation between different scene components.
- Blended-NeRF is an innovative approach that allows ROI-based editing of NeRF scenes guided by text prompts or image patches.
- Blended-NeRF enables the editing of any region of a scene while seamlessly blending with the existing scene, without requiring new feature spaces or masks.
- It leverages pre-trained language-image models like CLIP and a NeRF model for generating and blending new objects into scenes.
- Blended-NeRF provides a simple GUI for localized edits and proposes a novel distance smoothing operation for seamless blending.
- Incorporating augmentations and priors from previous works enhances the realism and coherence of the edited scenes.
Main AI News:
In recent years, various disciplines have experienced extraordinary breakthroughs, propelling us into a new era of possibilities. Notable advancements have emerged across different fields, ranging from language models with ChatGPT to generative models leveraging stable diffusion. However, one groundbreaking technique has taken the computer graphics and vision domain by storm: neural radiance fields (NeRF).
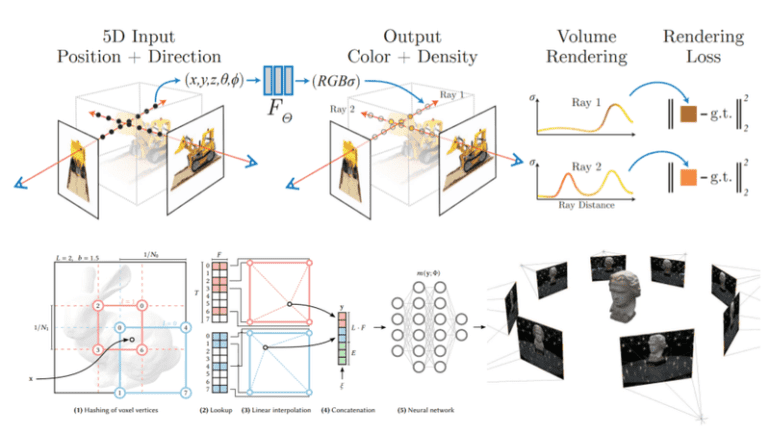
NeRF has revolutionized the way we represent and render 3D scenes, unlocking a realm of possibilities previously unimaginable. Unlike traditional explicit representations, NeRF encodes geometry and appearance information within a continuous 3D volume using neural networks. This unique approach allows for the synthesis of novel views and the accurate reconstruction of complex scenes, resulting in breathtaking photorealism and intricate detail fidelity.
The capabilities and potential of NeRF have sparked widespread interest, leading to extensive research efforts aimed at enhancing its functionality and addressing its limitations. Innovations ranging from accelerated NeRF inference to handling dynamic scenes and enabling scene editing have expanded the applicability and impact of this groundbreaking representation.
However, despite these remarkable advancements, NeRF still faces limitations that hinder its adaptability in practical scenarios. One significant example is the challenge of editing NeRF scenes, stemming from the implicit nature of NeRFs and the absence of explicit separation between different scene components. Unlike methods employing explicit representations like meshes, NeRFs lack a clear distinction between shape, color, and material. Moreover, seamlessly blending new objects into NeRF scenes requires maintaining consistency across multiple views, further complicating the editing process.
The ability to capture 3D scenes is just the beginning; the power to edit and manipulate the output is equally crucial. Digital images and videos possess their strength through the ease of editing, particularly with the advent of text-to-X AI models that enable effortless modifications. Now, it is time to introduce the game-changer: Blended-NeRF.
Blended-NeRF is an innovative approach to ROI-based editing of NeRF scenes, guided by text prompts or image patches. This revolutionary technique empowers users to edit any region of a real-world scene while preserving the integrity of the rest of the scene, eliminating the need for new feature spaces or sets of two-dimensional masks. The ultimate goal is to generate natural-looking and view-consistent results that seamlessly blend with the existing scene. Remarkably, Blended-NeRF is not confined to a specific class or domain, enabling complex text-guided manipulations such as object insertion/replacement, object blending, and texture conversion.
Realizing these remarkable features is no easy feat. Blended-NeRF leverages a pre-trained language-image model, such as CLIP, along with a NeRF model initialized on an existing scene, serving as the generator for synthesizing and blending new objects into the scene’s region of interest (ROI). The CLIP model guides the generation process based on user-provided text prompts or image patches, facilitating the creation of diverse 3D objects that seamlessly integrate with the scene. To enable localized edits while preserving the scene’s overall context, users are presented with a simple GUI that assists in localizing a 3D box within the NeRF scene, utilizing depth information to provide intuitive feedback. For achieving seamless blending, a novel distance smoothing operation is proposed, merging the original and synthesized radiance fields by skillfully blending the sampled 3D points along each camera ray.
Nevertheless, even with these remarkable advancements, a crucial hurdle remained: editing NeRF scenes using this pipeline often resulted in low-quality, incoherent, and inconsistent outcomes. To overcome this challenge, the researchers behind Blended-NeRF incorporated augmentations and priors from previous works, such as depth regularization, pose sampling, and directional-dependent prompts. These additions contribute to more realistic and coherent results, elevating the potential of Blended-NeRF to new heights.
Conclusion:
The emergence of Blended-NeRF signifies a significant leap forward in the field of 3D scene editing. By allowing for intuitive and text-guided manipulations while maintaining photorealism and detail fidelity, Blended-NeRF opens up new possibilities for creators and artists. This innovation has the potential to drive advancements in the market for 3D graphics and visualization, empowering professionals to generate and edit scenes with unprecedented realism and complexity.