
- Brown University presents LexC-Gen, an AI solution for generating data in low-resource languages.
- Traditional methods lack overlap with task data, hindering progress in NLP for low-resource languages.
- LexC-Gen uses lexicon-based cross-lingual data augmentation to bridge this gap effectively.
- It leverages bilingual lexicons and Controlled-Text Generation for scalable data generation.
- LexC-Gen outperforms baselines in sentiment analysis and topic classification tasks across 17 languages.
- Its practicality, efficiency, and compatibility with LLMs enhance accessibility and applicability.
Main AI News:
Addressing the challenge of data scarcity in low-resource languages, researchers at Brown University propose LexC-Gen, a pioneering artificial intelligence solution. Traditional methods rely on word-to-word translations from high-resource languages, yet they often lack the necessary overlap with task data, resulting in inadequate translation coverage. This scarcity of labeled data exacerbates the gap in natural language processing (NLP) advancements between high-resource and low-resource languages.
LexC-Gen innovatively tackles this issue by employing lexicon-based cross-lingual data augmentation. By leveraging bilingual lexicons, it swaps words in high-resource language datasets with their translations, thereby generating data tailored for low-resource languages. This method proves effective across various NLP tasks, including machine translation, sentiment classification, and topic classification. However, existing approaches encounter challenges related to domain specificity and the quality of training data in target low-resource languages.
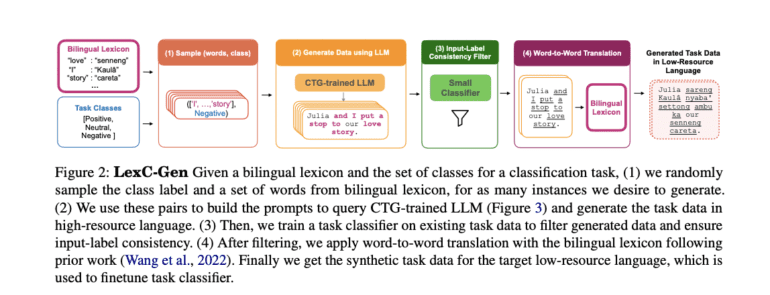
In response, Brown University researchers introduced LexC-Gen, a method designed for the scalable generation of low-resource-language classification task data. This groundbreaking approach capitalizes on bilingual lexicons to create lexicon-compatible task data in high-resource languages, which is then translated into low-resource languages. Crucially, LexC-Gen’s effectiveness hinges on conditioning its process on bilingual lexicons.
This method showcases practicality and efficiency, requiring only a single GPU for scalable data generation. Moreover, it remains compatible with open-access Large Language Models (LLMs), further enhancing its accessibility and applicability.
LexC-Gen’s methodology involves a systematic, multi-step process. It begins by sampling high-resource-language words and class labels, followed by the generation of lexicon-compatible task data using a Controlled-Text Generation (CTG)-trained LLM. Subsequently, an input-label consistency filter is applied before translating the data into the low-resource language via word-to-word translation facilitated by the bilingual lexicon.
Through extensive evaluation against baselines and gold translations on sentiment analysis and topic classification tasks, LexC-Gen emerges as a superior solution. Across 17 low-resource languages, it consistently outperforms baselines, demonstrating significant improvements in both sentiment analysis and topic classification tasks. For instance, combining LexC-Gen-100K with existing English data leads to a remarkable performance boost of 15.2 points in sentiment analysis and 18.3 points in topic classification, surpassing cross-lingual zero-shot and word translation baselines.
Conclusion:
LexC-Gen introduces a transformative approach to address the data scarcity challenge in low-resource languages. Its superior performance in sentiment analysis and topic classification tasks signifies a significant advancement in NLP capabilities for diverse linguistic communities. This innovation holds immense potential for businesses and organizations seeking to expand their reach and impact in global markets by tapping into previously underserved language demographics.