
- Carnegie Mellon University researchers have introduced a new objective called the regret gap for multi-agent imitation learning (MAIL).
- This approach addresses the challenge of coordinating strategic agents, such as routing drivers, without requiring explicit utility functions.
- Traditional imitation learning methods, including behavioral cloning and inverse reinforcement learning, face limitations such as covariate shifts and sample inefficiencies.
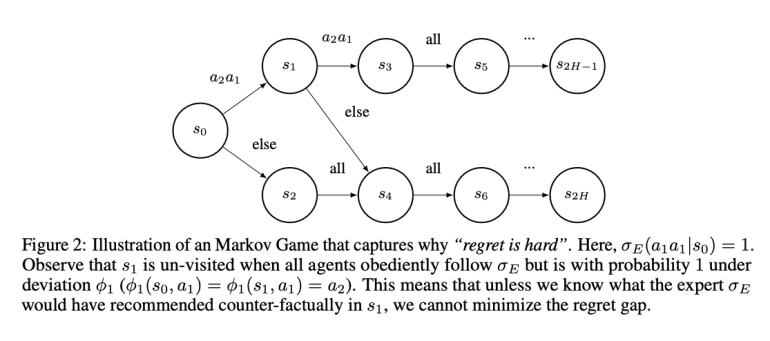
- The regret gap approach considers potential deviations by agents, showing that while value gap minimization is feasible, regret equivalence is more complex to achieve.
- Researchers developed two algorithms: MALICE, an extension of the ALICE algorithm for multi-agent settings, and BLADES, which incorporates a queryable expert.
- MALICE uses importance sampling and ensures a linear-in-H bound on the value gap, while BLADES enhances performance with queryable expert access.
- Single-agent imitation learning methods, like Joint Behavior Cloning (J-BC) and Joint Inverse Reinforcement Learning (J-IRL), adapt to multi-agent settings, maintaining similar value gap bounds.
- The study highlights the complexity of achieving regret equivalence compared to value equivalence, with MALICE providing an effective solution for minimizing regret gaps.
Main AI News:
Researchers from Carnegie Mellon University have made significant strides in the realm of multi-agent imitation learning (MAIL) by proposing a groundbreaking objective known as the regret gap. This new approach addresses the complex challenge of coordinating strategic agents, such as routing drivers through a road network, without relying on explicit utility functions.
The core issue in this domain lies in the difficulty of specifying the quality of action recommendations manually. To navigate this challenge, researchers have transformed the problem into one of multi-agent imitation learning. This shift raises critical questions about identifying the appropriate objectives for the learner. The study particularly focuses on the development of personalized route recommendations, exploring how different methodologies can address the nuances of MAIL.
Current research methods in imitation learning include single-agent techniques like behavioral cloning and inverse reinforcement learning. Behavioral cloning simplifies imitation to supervised learning but is plagued by covariate shifts and compounding errors. In contrast, inverse reinforcement learning allows learners to observe the consequences of their actions, thus avoiding compounding errors but often suffers from sample inefficiency. Multi-agent imitation learning introduces the concept of regret gap, yet it has not been fully utilized within Markov Games. Meanwhile, inverse game theory aims to recover utility functions rather than learning coordination from demonstrations.
The Carnegie Mellon researchers have introduced a novel objective for MAIL in Markov Games, focusing on the regret gap. This approach explicitly considers potential deviations by agents within the group. Their findings reveal that while single-agent imitation learning algorithms can minimize the value gap, they do not prevent the regret gap from becoming arbitrarily large. This discovery suggests that achieving regret equivalence is significantly more challenging than value equivalence in MAIL.
To address this, the researchers developed two efficient algorithms: MALICE and BLADES. MALICE is an extension of the ALICE algorithm, tailored for multi-agent environments. It employs importance sampling to adjust the learning policy based on expert demonstrations, ensuring a linear-in-H bound on the value gap under a recoverability assumption. BLADES, on the other hand, incorporates a queryable expert to further enhance performance. These algorithms provide robust solutions for minimizing the regret gap and offer practical benefits for real-world applications.
While the value gap is considered a ‘weaker’ objective, it remains relevant in scenarios involving non-strategic agents. Single-agent imitation learning algorithms can efficiently minimize the value gap, making it achievable in MAIL contexts. The study utilizes Joint Behavior Cloning (J-BC) and Joint Inverse Reinforcement Learning (J-IRL) to adapt single-agent methods to multi-agent settings, achieving comparable value gap bounds as in single-agent scenarios.
Overall, the research underscores the complexity of achieving regret equivalence compared to value equivalence in multi-agent systems. MALICE stands out as a particularly effective method for addressing the regret gap, extending the ALICE framework to accommodate the intricacies of multi-agent environments. This advancement marks a significant step forward in multi-agent imitation learning, offering new insights and practical solutions for coordinating strategic agents.
Conclusion:
Carnegie Mellon University’s introduction of the regret gap objective for multi-agent imitation learning represents a significant advancement in the field. By addressing the limitations of traditional methods and providing new algorithms like MALICE and BLADES, this research offers a more nuanced approach to coordinating strategic agents. The ability to effectively manage regret gaps has important implications for real-world applications, particularly in areas requiring sophisticated coordination of multiple agents. This development positions MAIL as a more robust and applicable solution in complex environments, potentially driving innovation and improvements in fields such as autonomous systems and route optimization.