
TL;DR:
- CatBERTa, a Transformer-based AI model, enhances energy prediction in catalyst research.
- Catalysts drive chemical reactions without consumption and impact clean energy and pharmaceuticals.
- Traditional methods, like Density Functional Theory (DFT), have limitations in catalyst material evaluation.
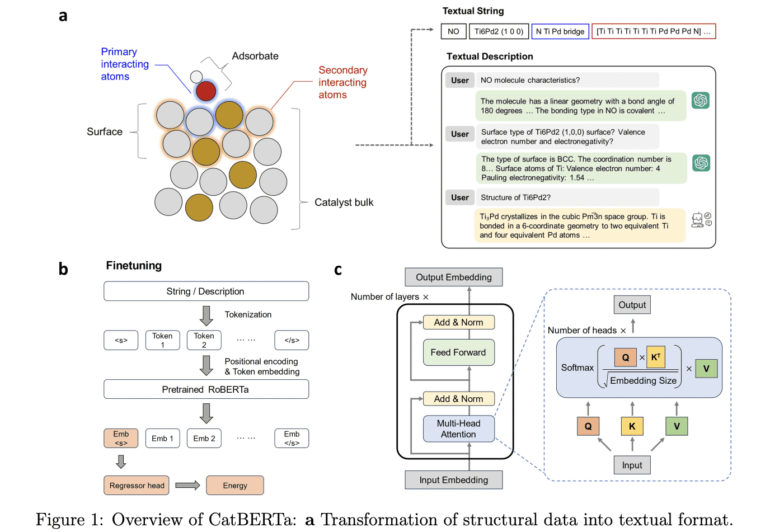
- CatBERTa’s unique traits include deciphering human-readable text data and improving model interpretability.
- It focuses on essential tokens in input text, particularly related to adsorbates and catalyst composition.
- Interacting atoms’ role in adsorption configurations is highlighted.
- CatBERTa predicts adsorption energy with a mean absolute error (MAE) of 0.75 eV, comparable to Graph Neural Networks (GNNs).
- It can significantly reduce systematic errors in chemically identical systems by up to 19.3%.
Main AI News:
In the ever-evolving realm of chemical catalyst research, the pursuit of innovative and enduring solutions remains a perpetual endeavor. Catalysts, the bedrock of contemporary industry, hold the power to expedite chemical reactions without undergoing consumption themselves. Their impact extends far and wide, propelling the realms of cleaner energy generation and pharmaceutical advancements. Nonetheless, the quest for optimal catalyst materials has historically been an arduous journey, necessitating intricate quantum chemistry computations and extensive experimental trials.
At the heart of crafting sustainable chemical processes lies the pursuit of ideal catalyst materials tailored for specific chemical reactions. While techniques like Density Functional Theory (DFT) have proven effective, they exhibit certain limitations. This stems from the resource-intensive nature of evaluating a myriad of catalysts. Relying solely on DFT calculations becomes problematic due to the multifaceted nature of catalysts, where a single bulk catalyst can feature myriad surface orientations, each susceptible to diverse adsorbate attachments.
In response to these challenges, a cohort of pioneering researchers has introduced CatBERTa, a Transformer-based AI model engineered for energy prediction harnessing textual inputs. CatBERTa stands atop the foundation of a pre-trained Transformer encoder, a deep learning marvel renowned for its exceptional prowess in natural language processing tasks. A distinctive hallmark of CatBERTa is its proficiency in deciphering human-readable text data while incorporating target features essential for adsorption energy prediction. This innovation translates complex data into a comprehensible format, enhancing the model’s usability and interpretability, a critical facet of its predictive capabilities.
One of the pivotal insights gleaned from the analysis of CatBERTa’s attention ratings is its proclivity to focus on specific tokens within the input text. These tokens pertain to adsorbates—substances that adhere to surfaces—alongside the overall composition of the catalyst and the interplay between these elements. CatBERTa’s prowess lies in its ability to identify and assign significance to the fundamental facets of catalytic systems, exerting an influential impact on adsorption energy.
Furthermore, this groundbreaking study underscores the pivotal role played by interacting atoms as key descriptors of adsorption configurations. The interaction between adsorbate atoms and those within the bulk material serves as a linchpin in catalytic processes. Notably, factors such as link length and the atomic composition of interacting atoms exhibit minimal influence on the precision of adsorption energy predictions. This finding implies that CatBERTa excels in prioritizing essential elements pertinent to the task at hand, effectively distilling crucial insights from textual inputs.
In terms of predictive accuracy, CatBERTa stands as a formidable contender, boasting a mean absolute error (MAE) of merely 0.75 eV when forecasting adsorption energy. This level of precision aligns seamlessly with the benchmark set by Graph Neural Networks (GNNs), the stalwarts of predictive modeling in this domain. Additionally, CatBERTa introduces a noteworthy advantage—when applied to chemically identical systems, it has the potential to substantially mitigate systematic errors, reducing them by an impressive 19.3% upon subtraction. This revelation underscores the pivotal role CatBERTa plays in catalyst screening and reactivity assessment, presenting a promising avenue for the rectification of energy forecasting inaccuracies.
Conclusion:
CatBERTa represents a significant leap in catalyst research, offering improved accuracy and interpretability in energy prediction. This innovation has the potential to revolutionize the market by streamlining catalyst screening and reactivity assessment, paving the way for more efficient and sustainable chemical processes. Businesses and industries reliant on catalysts stand to benefit from the precision and insights CatBERTa brings to the table, driving advancements in clean energy and pharmaceuticals.