
- Cerebras has launched two advanced models in the DocChat series: Cerebras Llama3-DocChat and Cerebras Dragon-DocChat.
- These models are designed for document-focused Q&A tasks and were developed with exceptional speed using Cerebras’ cutting-edge technology.
- Llama3-DocChat is built on the Llama 3 framework, integrating insights from Nvidia’s ChatQA and using synthetic data to address limitations.
- Dragon-DocChat is optimized for multi-turn retrieval, improving recall rates significantly over competitors.
- The models were trained efficiently, setting a new industry benchmark for speed and performance.
- Both models have achieved top-tier results across benchmarks, demonstrating superior capabilities in complex Q&A tasks.
- Cerebras has made the models, training recipes, and datasets available to the open-source community, promoting further innovation.
- The development faced challenges addressed through innovative techniques, particularly with handling unanswerable questions and improving arithmetic performance.
- Cerebras plans future enhancements, including support for longer contexts, better mathematical reasoning, and larger model sizes.
Main AI News:
Cerebras has made a significant leap in document-based conversational AI with the launch of DocChat. Renowned for its deep expertise in machine learning and large language models, Cerebras has unveiled two innovative models under the DocChat series: Cerebras Llama3-DocChat and Cerebras Dragon-DocChat. These models, designed with precision to excel in document-focused Q&A tasks, were developed at an unprecedented speed thanks to Cerebras’ cutting-edge technology.
The Cerebras Llama3-DocChat model is built on the Llama 3 framework, integrating advanced insights from recent research, including Nvidia’s ChatQA model series. The development process harnessed Cerebras’ extensive experience training large language models and curating datasets alongside pioneering techniques like synthetic data generation. This comprehensive approach enabled Cerebras to tackle limitations that existing real-world data couldn’t fully resolve.
Cerebras Dragon-DocChat, on the other hand, is a multi-turn retriever model optimized to enhance recall rates. This model was trained on the ChatQA conversational Q&A dataset and further refined using contrastive loss with hard negatives, leading to substantial improvements in recall rates compared to its predecessors and rivals.
A key highlight of the DocChat series is the remarkable speed at which these models were trained. The Cerebras Llama3-DocChat model was fully trained using a single Cerebras System in a few hours, while the Dragon-DocChat model was fine-tuned within minutes. This efficiency is a testament to Cerebras’ advanced hardware and software, setting a new benchmark in the industry.
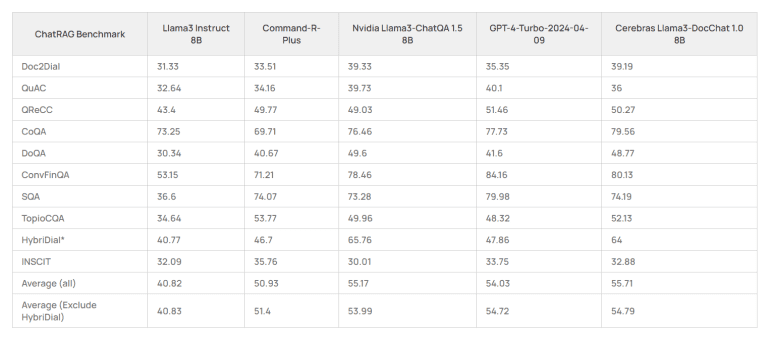
The performance of these models has been thoroughly validated across numerous benchmarks, where they consistently achieved top-tier results for their respective sizes. For instance, on benchmarks such as ConvFinQA and SQA, the Cerebras Llama3-DocChat model demonstrated significant improvements, underscoring its superior ability to handle complex conversational Q&A scenarios.
Cerebras has also reaffirmed its commitment to the open-source community by releasing DocChat. The company has freely made the model weights, comprehensive training recipes, and associated datasets available. This transparency empowers other AI researchers and developers to replicate, build upon, and innovate using Cerebras’ work, fostering further advancements in the field.
In head-to-head comparisons, Cerebras’ DocChat models have shown impressive results. For example, in the ChatRAG Benchmark, Cerebras Llama3-DocChat outperformed Nvidia’s Llama3-ChatQA and GPT-4 Turbo across several key metrics. Similarly, Cerebras Dragon-DocChat excelled in recall rates, surpassing Facebook’s Dragon+ and Nvidia’s Dragon Multiturn, particularly in multi-turn conversational settings.
The journey to developing DocChat was challenging. One of the primary issues was improving the model’s response to unanswerable questions. Early testing revealed that the model often struggled with such queries, sometimes providing inappropriate responses. By strategically upsampling unanswerable question samples, Cerebras enhanced the model’s performance, though the company acknowledges that further refinement is necessary, especially when benchmarked against leading models like QuAC and DoQA.
Another challenge involved improving the model’s arithmetic capabilities, which initially suffered from errors. By incorporating techniques inspired by the Chain of Thought (CoT) method, Cerebras significantly enhanced the model’s accuracy in arithmetic tasks. Additionally, entity extraction posed challenges due to a lack of high-quality training data. This issue was addressed by integrating a subset of SKGInstruct, an instruction-tuning dataset that improved the model’s performance in entity extraction tasks.
Looking ahead, Cerebras has ambitious plans for the future of the DocChat series. The company is exploring enhancements such as support for longer contexts, improved mathematical reasoning, and the development of larger model sizes. These advancements are expected to further solidify Cerebras’ leadership in conversational AI.
Conclusion:
Cerebras’ introduction of the DocChat models marks a significant shift in the AI-driven document Q&A market. The combination of speed, performance, and open-source transparency sets a new standard for the industry, challenging competitors to innovate or risk being left behind. The market can expect increased competition, with a strong focus on efficiency and model performance, particularly in specialized applications like document-based conversational AI. Cerebras’ commitment to continuous improvement and its strategic focus on addressing key challenges signal its intent to lead the market, likely driving further advancements and setting new benchmarks in the field.