
TL;DR:
- Cerebras introduces BTLM-3B-8K, a cutting-edge 3B parameter open-source language model.
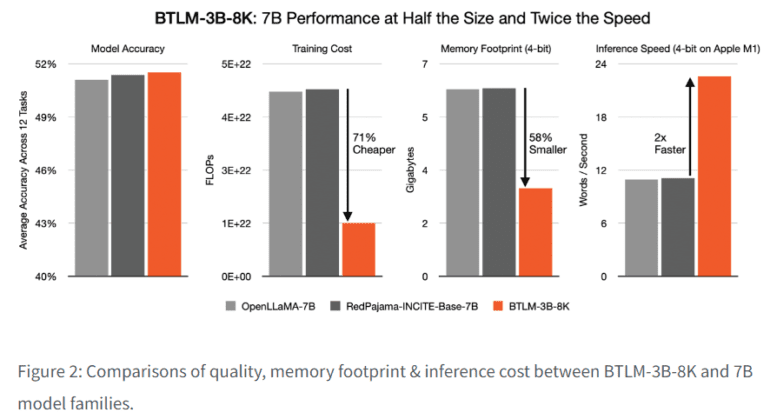
- This model rivals 7B parameter models with fewer parameters, less computation, and equal context length.
- BTLM-3B-8K enables 7B model performance on edge devices with limited memory.
- It outperforms 7B models in various benchmarks, demonstrating superior capabilities.
- The model’s methodology, enhanced instruction, and data availability contribute to its success.
Main AI News:
In today’s fast-paced world, large language models (LLMs) have become indispensable tools for a wide range of applications, from content creation to computer programming and natural language interpretation. These models have transformed the way we interact with information, enabling us to generate meaningful content, answer questions, translate languages, and condense lengthy materials with ease. Thanks to groundbreaking work by LLaMa Touvron et al., it is now possible to efficiently train LLMs on billions of tokens, achieving state-of-the-art parameter efficiency. This development ushered in a new era of open-source LLMs that could run seamlessly on high-end laptops.
Over time, LLaMa models have evolved and expanded, with the 7B parameter size becoming the go-to choice for its effectiveness and versatility. However, the demands placed on memory and computing power by these models have made them impractical for many situations. Edge devices, such as smartphones and laptops, often lack the memory capacity to handle the weight of 7B model parameters, resulting in sluggish performance even with optimization techniques like quantization. Furthermore, the need for LLMs to process extensive contexts has posed a challenge. The ability to model long-range contextual relationships is crucial for tasks such as summarization, code analysis, DNA sequence prediction, multi-turn conversations, and content generation for articles.
In response to these challenges, a team of researchers from Cerebras Systems and the OpenTensor Foundation introduced the groundbreaking BTLM-3B-8K, a state-of-the-art 3B parameter open-source language model. This remarkable model not only rivals 7B parameter models but does so with significantly fewer parameters, less computation, and fewer tokens during training. With just 2.5 times less inference computation than its 7B counterparts and the ability to operate on devices with as little as 3GB of RAM, BTLM-3B-8K empowers users to harness the performance of 7B models on billions of edge devices worldwide. What’s more, BTLM-3B-8K utilizes ALiBi position embedding and boasts an impressive context length of up to 8,192, putting it on par with 7B parameter models already in use.
The researchers behind BTLM-3B-8K have made significant contributions in various areas:
- Training Methodology: Leveraging the power of CG-1, a cluster of 64 Cerebras CS-2 Systems, they detail the methodology used to train BTLM-3B-8K on a single epoch of the SlimPajama dataset.
- Model Assessment: They provide a comprehensive comparison of 3B and 7B parameter models across 22 benchmarks, evaluating factors such as common sense reasoning, general knowledge, reading comprehension, code generation, lengthy sequence extrapolation, bias, and disinformation. The results demonstrate that BTLM-3B-8K sets a new gold standard for 3B parameter models and frequently outperforms its 7B counterparts.
- Enhanced Instruction: The architectural modifications and training strategies that contribute to BTLM’s exceptional performance are thoroughly explained, resulting in a remarkable 5.36% improvement in loss over the baseline.
- Releases and Availability: The researchers have made the BTLM-3B-8K weights and the SlimPajama dataset accessible on Hugging Face. They believe that these contributions will greatly benefit the open-source community, further advancing the field of natural language processing.
Conclusion:
The introduction of BTLM-3B-8K marks a significant advancement in the language model landscape. Its ability to rival 7B parameter models while being more memory-efficient and accessible to edge devices positions it as a game-changer. This model opens up new possibilities for businesses seeking efficient natural language processing solutions and underscores the growing importance of accessible and high-performance language models in the market. Companies that harness the power of BTLM-3B-8K can gain a competitive edge in content generation, code analysis, and various other applications, making it a pivotal development for the business world.