
TL;DR:
- Galileo’s research highlights ChatGPT-4’s excellence in multitasking among Large Language Models (LLMs).
- Hallucination, a persistent issue in LLMs, can lead to inaccurate results.
- Galileo’s study assessed 11 LLMs and found ChatGPT-4 to be the most reliable.
- Metrics like Correctness and Context Adherence were used to identify hallucination instances.
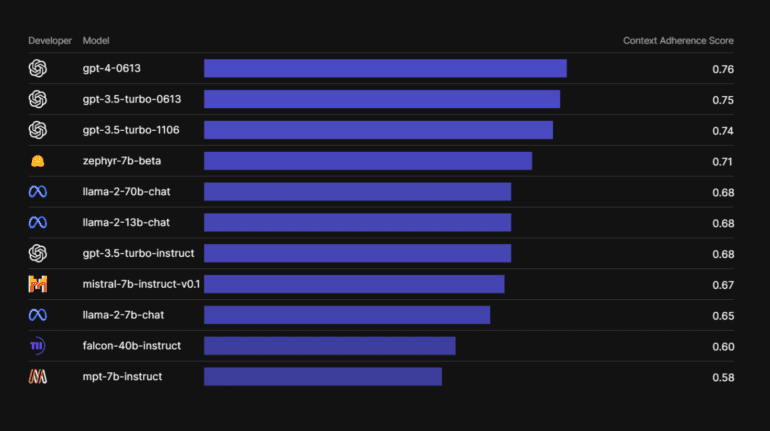
- GPT-4(0613) scored the highest in correctness and information retrieval.
- ChatGPT-4 excelled in generating long-form content.
- Considerations about pricing and alternatives like GPT 3.5 and LLama-2-70b are important for enterprises.
Main AI News:
In the realm of cutting-edge Large Language Models (LLMs), Galileo, a San Francisco-based company specializing in LLM applications, has conducted groundbreaking research into the phenomenon of hallucination among these AI behemoths. Hallucination, the tendency of LLMs to produce inaccurate and baseless results, has long plagued the field. However, Galileo’s recent study has unveiled a standout performer in the form of ChatGPT-4, which demonstrates exceptional multitasking prowess with minimal hallucination.
The Challenge of LLM Reliability in Enterprise Settings Enterprises increasingly harness the power of AI and LLMs to bolster their operations. Yet, the reliability of LLMs in real-world applications remains a pressing concern. These models operate based on the data they are provided, often without verifying the factual accuracy of the information. When developing generative AIs, crucial considerations include whether they are designed for general use or tailored as ChatBots for enterprise-specific needs.
While companies employ benchmarks to assess LLM performance, the unpredictable occurrence of hallucinations continues to pose challenges. In response to this critical issue, Galileo’s co-founder, Atindriyo Sanyal, undertook a meticulous examination of 11 LLMs, spanning diverse sizes and capabilities, to evaluate their performance. Sanyal subjected these LLMs to a battery of general questions using TruthfulQA and TriviaQA to monitor their susceptibility to hallucination.
Galileo’s Precision Metrics: Unmasking LLM Hallucination Galileo employed two key metrics, Correctness and Context Adherence, which serve as invaluable tools for engineers and data scientists. These metrics shed light on the precise moments when LLMs tend to hallucinate, pinpointing logic-based errors in their responses.
Correctness Scores Unveiled Following extensive interactions with LLMs, Galileo derived a noteworthy correctness score for each model. Leading the pack was GPT-4 (0613) with an impressive score of 0.77, closely trailed by GPT-3.5 Turbo(1106) at 0.74. GPT-3.5 Turbo Instruct and GPT-3.5 Turbo(0613) both garnered a respectable 0.70 correctness score. Meta’s Llama-2-70b followed with a score of 0.65, while Mosaic ML’s MPT-7b lagged behind with a score of 0.40.
In the realm of information retrieval, GPT-4(0613) once again demonstrated its mettle, boasting a commanding score of 0.76. Hugging Face’s Zephyr-7b outperformed Llama in this category with a score of 0.71, while Llama secured a respectable 0.69 score. The LLMs in need of the most improvement, with correctness scores of 0.58 and 0.60, were Mosaic ML’s MPT-7b and UAE’s Falcon 40-b, respectively.
Masters of Long-Form Content When it comes to the art of generating lengthy textual compositions, such as essays and articles, GPT-4(0163) soared to the top with an impressive score of 0.83. Llama closely trailed with a score of 0.82. These two models exhibited remarkable resistance to hallucination when tasked with multiple assignments. In contrast, MPT-7b lagged behind with a score of 0.53.
Navigating the Cost of Correctness While ChatGPT-4 stands as a paragon of reliability, there is a caveat that may give pause to potential users – its pricing structure. GPT-4(0613) commands a fee for its services. However, GPT 3.5 offers comparable reliability in minimizing hallucination. Additionally, alternatives like LLama-2-70b deliver commendable performance and come at no cost, making them appealing choices for budget-conscious enterprises.
Conclusion:
Galileo’s findings underscore ChatGPT-4’s supremacy in minimizing hallucination among LLMs, making it an ideal choice for enterprises seeking reliable AI solutions. However, the pricing structure should be weighed against alternatives like GPT 3.5 and LLama-2-70b to determine the best fit for specific business needs in the evolving AI market.