
TL;DR:
- Computer science researchers at the University of Maryland have developed a groundbreaking dataset called Chop & Learn.
- Chop & Learn aims to teach machine learning systems to recognize various forms of produce, even as they undergo dynamic transformations like peeling, slicing, or chopping.
- The dataset was presented at the 2023 International Conference on Computer Vision in Paris.
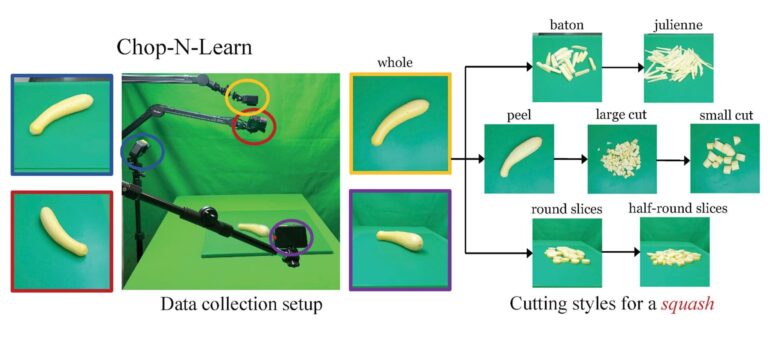
- It was created by filming 20 types of fruits and vegetables being prepared in seven different styles from four angles.
- The diversity in preparation styles is crucial for training the computer to recognize subtle differences.
- This dataset has the potential to advance fields such as 3D reconstruction, video generation, and long-term video analysis.
- It could impact safety features in autonomous vehicles and improve public safety threat identification.
- Additionally, it might contribute to the development of a robotic chef capable of preparing healthy meals from fresh produce.
Main AI News:
In the realm of computer vision, the last few years have witnessed remarkable strides; however, one persistent challenge continues to baffle the field: training machines to identify objects amidst their dynamic transformations, especially within the domain of artificial intelligence (AI) systems. This complex conundrum has now met its match in the form of Chop & Learn, an ingenious dataset conceived by computer science researchers at the University of Maryland.
Chop & Learn’s primary mission is to educate machine learning systems in the art of recognizing produce in its multifarious guises – be it as a pristine fruit or in the throes of being peeled, sliced, or chopped into myriad fragments. This groundbreaking project, unveiled at the esteemed 2023 International Conference on Computer Vision in Paris, marks a significant leap in the ongoing quest for AI systems that can adapt to the evolving world around them.
Nirat Saini, a seasoned fifth-year computer science doctoral student and the lead author of the paper, explained, “You and I can effortlessly visualize the distinction between a sliced apple or orange and a whole fruit, but for machine learning models, grasping such nuances demands copious amounts of data.” She further emphasized, “We had to devise a methodology that enables computers to conjure up unseen scenarios much like the way humans do.”
To materialize this vision, Saini and her cohorts, Hanyu Wang and Archana Swaminathan, fellow doctoral students in computer science, embarked on an ambitious journey of capturing 20 different types of fruits and vegetables undergoing seven distinct styles of preparation, meticulously recorded from four different angles using an array of video cameras. The diversity in angles, people, and food preparation techniques is pivotal in constructing a comprehensive dataset, as Saini noted, “Individuals may have their own idiosyncratic approach, like peeling an apple or potato before chopping, and the computer must discern these subtleties.“
The Chop & Learn team comprises not only Saini, Wang, and Swaminathan but also computer science doctoral students Vinoj Jayasundara and Bo He, along with Kamal Gupta, who completed his Ph.D. in 2023 and is now associated with Tesla Optimus. Their mentor, Abhinav Shrivastava, an assistant professor of computer science with an affiliation with the University of Maryland Institute for Advanced Computer Studies, shared his perspective: “The ability to discern objects undergoing diverse transformations is pivotal for the development of long-term video understanding systems.” He added, “Our dataset serves as a promising foundation for addressing the fundamental crux of this challenge.”
In the immediate future, Shrivastava envisions that the Chop & Learn dataset will contribute significantly to advancements in image and video-related tasks, such as 3D reconstruction, video generation, and the succinct summarization and parsing of extended video footage. These strides could potentially revolutionize fields ranging from the integration of safety features in autonomous vehicles to bolstering public safety measures by aiding in the identification of potential threats.
While not an immediate goal, Shrivastava speculates that Chop & Learn could play a role in the development of a robotic chef capable of transforming fresh produce into delectable and nutritious meals with a simple command in the comfort of one’s kitchen. The future appears ripe with possibilities as Chop & Learn continues to shape the future of machine learning and computer vision.
Conclusion:
The creation of the Chop & Learn dataset represents a significant breakthrough in object recognition for machine learning. Its potential applications span various industries, from enhancing video analysis to improving safety measures in autonomous vehicles. This innovative dataset is poised to drive advancements in AI and computer vision technologies, opening up new opportunities in the market for cutting-edge solutions and applications.