
TL;DR:
- Clinical NLP faces challenges due to complex terminology and privacy concerns.
- Large language models (LLMs) offer potential but come with computational and privacy issues.
- Synthetic training data with LLMs is a promising solution.
- CLINGEN, an AI framework, combines LLMs with clinical knowledge extraction.
- CLINGEN enhances data variety, aligns with original data, and improves performance.
- It can be applied to various clinical NLP tasks with minimal human effort.
Main AI News:
In the realm of clinical natural language processing (NLP), the extraction, analysis, and interpretation of medical data from unstructured clinical literature have posed significant challenges. These challenges stem from the intricate nature of clinical texts, which often brim with acronyms and specialized medical terminology. However, a ray of hope has emerged in the form of recent advancements in large language models (LLMs). These models, pre-trained on extensive corpora and boasting billions of parameters, have the innate capacity to capture substantial clinical insights.
The emergence of LLMs underscores the need for tailored methods to adapt them for clinical applications, addressing the complexity of medical terminology and fine-tuning these models with clinical data. While generic LLMs offer great potential, employing them directly for clinical text analysis in real-world settings can be less than ideal. These models come with massive computational requirements, resulting in high infrastructure costs and protracted inference times. Moreover, the sensitivity of clinical text, containing patient information, raises valid concerns about privacy and regulatory compliance. Enter the potential solution: generating synthetic training data with LLMs, harnessing their capabilities in a resource-efficient and privacy-conscious manner.
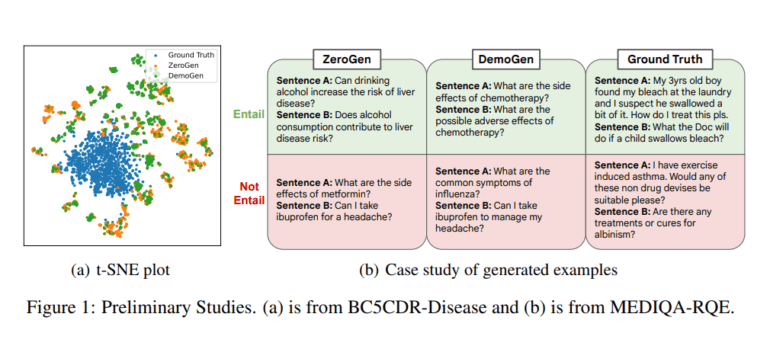
By training models on synthetic datasets, it becomes possible to achieve high-performance levels while adhering to stringent data privacy regulations. These synthetic datasets can faithfully replicate real-world clinical data. However, creating clinical data through LLMs poses unique challenges in ensuring data quality that mirrors the original dataset’s distribution. To assess the quality of data generated by existing techniques, an exhaustive analysis focusing on diversity and distribution metrics is imperative. Notably, metrics such as the Central Moment Discrepancy (CMD) score and t-SNE embedding visualization often reveal significant shifts in data distribution.
Furthermore, examining the presence and frequency of clinically relevant entities in synthetic data unveils a substantial decrease when compared to ground truth data. Many prior studies have delved into the creation of clinical data using language models, but these initiatives have been predominantly task-specific. Examples include electronic health records, clinical notes, medical text mining, and medical conversations. These studies often rely on language models for text generation, but the scope for improving how LLMs are adapted to produce synthetic clinical text for downstream applications is vast.
Inspired by these challenges, a collaborative effort between researchers from Emory University and Georgia Institute of Technology has given rise to CLINGEN. This innovative framework, infused with clinical expertise, aims to produce high-quality clinical texts in few-shot scenarios. Its primary objectives include enhancing subject variety in generated text and bridging the gap between synthetic and ground-truth data. To achieve these goals, CLINGEN leverages clinical knowledge extraction to contextualize prompts effectively. This entails drawing inspiration for clinical themes from knowledge graphs (KGs) and LLMs and seeking guidance on writing styles from LLMs. Thus, CLINGEN combines the parametric insights from big language models with non-parametric knowledge from external clinical knowledge graphs.
It is crucial to highlight that CLINGEN offers a user-friendly solution for various fundamental clinical NLP tasks, requiring minimal additional human intervention. In summary, the key contributions of this groundbreaking work include:
- Proposing CLINGEN, a versatile framework replete with clinical information, for generating clinical text data in few-shot scenarios.
- Presenting a straightforward yet efficient method to tailor prompts for clinical NLP tasks using clinical knowledge extraction, applicable across a range of clinical activities.
- Conducting a comprehensive analysis of synthetic clinical data generation using 16 datasets and addressing seven clinical NLP tasks. Experimental results demonstrate that CLINGEN augments the diversity of training samples while aligning more closely with the original data distribution. The empirical performance gains (8.98% for PubMedBERTBase and 7.27% for PubMedBERTLarge) remain consistent across various tasks, LLMs, and classifiers.
Conclusion:
CLINGEN’s innovative approach to clinical text generation presents a game-changing solution for the healthcare market. By bridging the gap between LLMs and clinical knowledge, it offers improved data quality, privacy compliance, and enhanced performance across various clinical NLP tasks. This technology has the potential to revolutionize how healthcare organizations leverage AI for data analysis and interpretation, leading to more efficient and accurate clinical insights.