
TL;DR:
- CMMMU introduces a Chinese benchmark for Large Multimodal Models (LMMs).
- It assesses LMMs across diverse multidisciplinary tasks.
- The benchmark features 12,000 Chinese multimodal questions from various disciplines.
- A rigorous data collection and quality control process ensures dataset richness and accuracy.
- Evaluation includes both closed-source and open-source LMMs under zero-shot settings.
- Error analysis highlights challenges even for top-performing LMMs.
- A smaller performance gap is observed between open-source and closed-source LMMs in Chinese compared to English.
Main AI News:
In the realm of artificial intelligence, Large Multimodal Models (LMMs) have showcased impressive problem-solving prowess across a myriad of tasks, from zero-shot image/video classification to multimodal question answering. Nevertheless, recent research has underscored a notable disparity between these powerful LMMs and expert-level artificial intelligence, particularly when tackling intricate perception and reasoning tasks that demand domain-specific knowledge. This article introduces CMMMU, an innovative Chinese benchmark meticulously crafted to assess LMMs’ performance across a wide spectrum of multidisciplinary challenges, guiding the development of bilingual LMMs toward attaining expert-level AI capabilities.
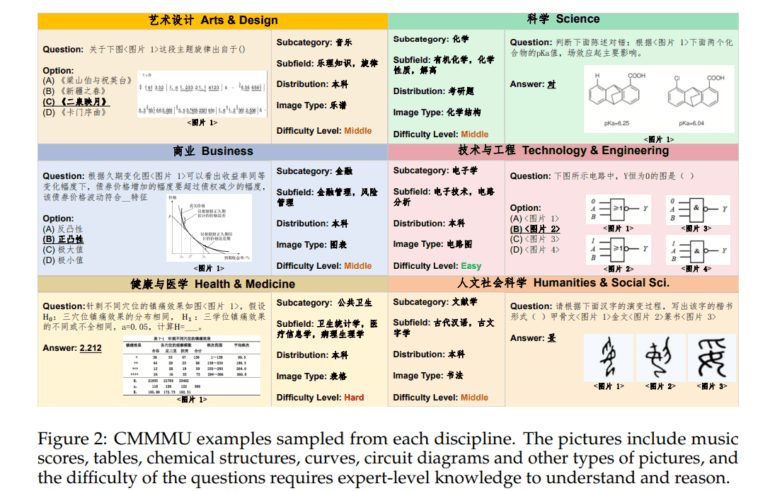
CMMMU, which stands for Chinese Massive Multi-discipline Multimodal Understanding, emerges as one of the most comprehensive benchmarks available, housing a curated collection of 12,000 Chinese multimodal questions meticulously sourced from college exams, quizzes, and textbooks. These questions traverse six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. This benchmark not only tests LMMs on intricate reasoning and perception tasks but also annotates each question with detailed subfields and image types, offering valuable insights into the types of questions that pose significant challenges for LMMs.
A meticulous three-stage data collection process guarantees the richness and diversity of CMMMU. In the first stage, organizers, primarily the authors, gather sources adhering to stringent license requirements. In the second stage, crowdsourced annotators, including undergraduate students and individuals with advanced degrees, further annotate the collected sources, meticulously adhering to key principles to filter out inadequate questions with accompanying images. The third stage involves supplementing questions in disciplines requiring more representation, ensuring a balanced dataset across various fields.
To further enhance data quality, a rigorous quality control protocol is implemented. Each question is manually verified by at least one of the paper’s authors, eliminating questions with answers deemed too challenging for LMMs to extract. Furthermore, questions failing to meet college-level examination standards are scrupulously removed. To mitigate data contamination concerns, questions that can be simultaneously solved by multiple advanced LMMs without OCR assistance are also filtered out.
The evaluation encompasses both large language models (LLMs) and large multimodal models (LMMs), encompassing both closed-source and open-source implementations. The assessment employs zero-shot evaluation settings instead of fine-tuning or few-shot settings, providing a raw assessment of the model’s ability to generate precise answers on multimodal tasks. A systematic, rule-based evaluation pipeline is employed, incorporating robust regular expressions and specific rules tailored to different question types, ensuring a comprehensive evaluation. Finally, micro-average accuracy is adopted as the primary evaluation metric.
Additionally, this paper conducts a meticulous error analysis on 300 samples, spotlighting instances where even top-performing LMMs, such as QwenVL-Plus and GPT-4V, provide incorrect answers. The analysis, distributed across 30 subjects, elucidates the challenges that can lead advanced LMMs astray and underscores the considerable journey ahead toward achieving expert-level bilingual LMMs. Remarkably, even the most advanced closed-source LMMs, GPT-4V and Qwen-VL-Plus, achieve only 42% and 36% accuracy, respectively, indicating substantial room for improvement.
Notably, the study unveils a narrower performance gap between open-source and closed-source LMMs in a Chinese context compared to English. While the most powerful open-source LMM, Qwen-VL-Chat, achieves an accuracy of 28%, with a 14% gap compared to GPT-4V, the gap in English is 21%. Yi-VL-6B1, Yi-VL-34B2, and Qwen-VL-Chat emerge as top-performing open-source LMMs on CMMMU, highlighting their potential in the Chinese language domain. Yi-VL-34B even narrows the performance gap between open-source LMMs and GPT-4V on CMMMU to 7%.
Conclusion:
The introduction of CMMMU, a comprehensive Chinese benchmark for Large Multimodal Models (LMMs), signifies a significant step towards advancing the capabilities of multimodal AI. It provides valuable insights into the performance of LMMs across various disciplines and challenges, offering a roadmap for the development of bilingual LMMs. The narrowing performance gap between open-source and closed-source LMMs in the Chinese context indicates growing potential in the Chinese language domain, promising opportunities for the AI market to expand its reach and effectiveness in the region.