
TL;DR:
- Researchers from CMU and NYU introduced LLMTime, a novel AI method for time series forecasting using Large Language Models (LLMs).
- Time series data’s unique challenges include diverse sources and missing values, making precise predictions challenging.
- LLMs, known for text and language tasks, bridge the gap between traditional methods and deep learning for time series forecasting.
- LLMTIME2, a key technique, treats time series as text, allowing the application of robust pretrained models and probabilistic capabilities.
- This approach outperforms purpose-built models without modifying downstream data, making it efficient and versatile.
- The zero-shot property simplifies LLM utilization and reduces the need for specialized fine-tuning, making it suitable for data-scarce scenarios.
- LLMs exhibit preferences for straightforward sequences and can represent multimodal distributions, enhancing their effectiveness.
- LLMs enable inquiries for additional contextual information and justifications for predictions.
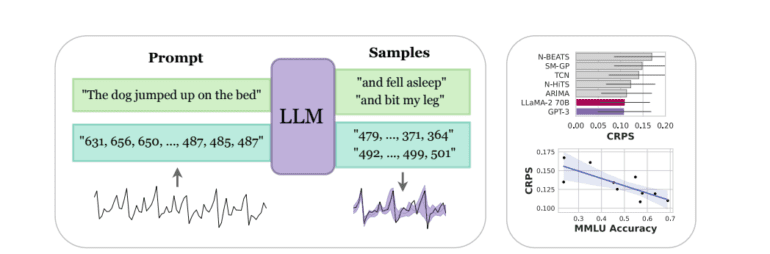
- GPT-4 exhibits weaker uncertainty calibration compared to GPT-3, possibly due to interventions like RLHF.
Main AI News:
In the world of time series forecasting, where precision and accuracy are paramount, researchers hailing from Carnegie Mellon University (CMU) and New York University (NYU) have introduced a groundbreaking method that leverages the power of Large Language Models (LLMs) to navigate the complexities of predicting the future. Termed LLMTime, this innovative approach addresses the unique challenges posed by time series data, setting it apart from its textual, auditory, or visual counterparts.
Time series data, unlike the neatly uniform input scales and sample rates found in audio and video data, often comprises sequences from a myriad of sources, replete with missing values. Take, for example, weather or financial data; they demand forecasts derived from incomplete observations, making precise predictions a formidable task. In such scenarios, the ability to estimate uncertainty becomes invaluable.
Historically, pretraining has not been a common practice in time series modeling, primarily due to the absence of a consensus on unsupervised objectives and the scarcity of comprehensive pretraining datasets. Contrastingly, large-scale pretraining has emerged as a linchpin in training neural networks, propelling performance in fields like computer vision and natural language processing. It is within this context that the researchers unveil how LLMs could potentially bridge the gap between traditional techniques, such as ARIMA and linear models, and the intricate realm of deep learning.
Introducing LLMTIME2, a straightforward approach that envisions time series forecasting as a next-token prediction task in the realm of text. This innovative perspective allows researchers to treat time series as a sequence of numerical digits, paving the way for the application of robust pretrained models and probabilistic capabilities like probability assessment and sampling. The method encompasses two key strategies: encoding time series efficiently as strings of numerical digits and converting discrete LLM distributions into continuous densities capable of describing complex multimodal distributions.
Intriguingly, LLMTIME showcases its mettle by outperforming or matching purpose-built time series models across various scenarios, all without necessitating adjustments to downstream data employed by other models. The zero-shot property of LLMTIME delivers a trifecta of advantages: it simplifies LLM utilization, obviates the need for specialized fine-tuning, and thrives in data-scarce environments. It also circumvents the laborious process of crafting domain-specific time series models by harnessing the broad pattern extrapolation prowess of extensively pretrained LLMs.
Delving deeper, the researchers explore how LLMs exhibit preferences for straightforward or repetitive sequences, aligning seamlessly with critical time series features such as seasonality. These models also excel in representing multimodal distributions and accommodating missing data, a boon for the intricacies of time series forecasting.
Furthermore, the capabilities of LLMs extend beyond prediction, enabling inquiries for additional contextual information and justifications for their forecasts. As the scale of LLMs grows, so does their forecasting prowess, with the quality of point forecasts intricately linked to the representation of uncertainty. Interestingly, the study highlights that GPT-4 exhibits a weaker uncertainty calibration compared to its predecessor GPT-3, possibly due to interventions such as reinforcement learning with human feedback (RLHF).
Conclusion:
LLMTime’s integration into time series forecasting marks a pivotal moment in the market. It not only enhances precision and accuracy but also simplifies the process, making it accessible even in data-scarce scenarios. This advancement signifies a potential paradigm shift, where businesses can leverage the power of pretrained models to gain a competitive edge in forecasting and decision-making.