
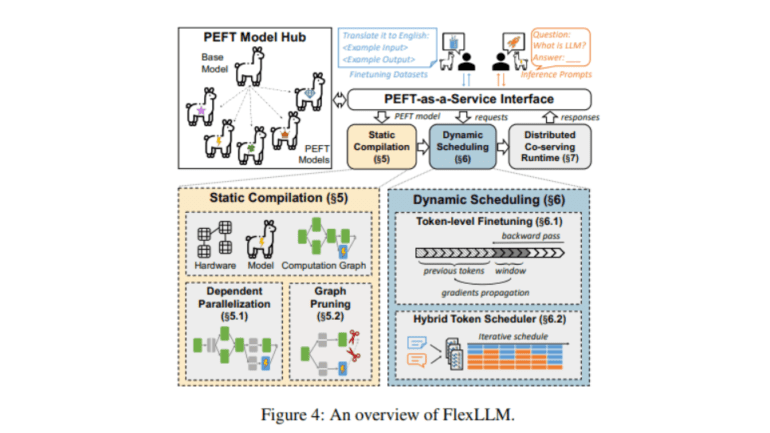
- FlexLLM, developed by CMU and Stanford researchers, optimizes LLM finetuning and inference tasks simultaneously.
- It leverages token-level finetuning and memory optimization strategies for enhanced efficiency.
- FlexLLM maintains over 80% of peak finetuning throughput even under heavy inference workloads.
- The system promises to democratize access to LLM deployment and foster innovation in natural language processing.
Main AI News:
In the realm of artificial intelligence, the proliferation of large language models (LLMs) has reshaped the landscape, enabling machines to comprehend and generate text akin to human conversation with unparalleled precision. These models have found widespread utility across diverse sectors, from content generation to automated customer service and language translation. Nonetheless, their practical deployment remains hampered by their sheer size, often comprising billions of parameters, rendering the finetuning process for specific tasks both computationally intensive and technically intricate.
A pioneering solution has emerged, aiming to streamline the finetuning of LLMs sans the need for extensive computational resources. Conventional approaches entail updating a substantial fraction of the model’s parameters, necessitating significant memory and processing capabilities. In contrast, contemporary methodologies prioritize adjustments to a smaller subset of parameters, thereby alleviating the computational burden. This paradigm, known as parameter-efficient finetuning (PEFT), has facilitated more pragmatic applications of LLMs by expediting and simplifying the finetuning process.
Enter FlexLLM, a groundbreaking system developed jointly by Carnegie Mellon University and Stanford University researchers. Engineered to seamlessly handle LLM inference and PEFT tasks on shared computational resources, FlexLLM capitalizes on the intrinsic complementarity of these tasks to optimize resource utilization, marking a substantial leap in efficiency vis-à-vis traditional segregated approaches.
At the heart of FlexLLM’s architecture lie two pivotal innovations: a token-level finetuning mechanism and an array of memory optimization strategies. The token-level approach dissects the finetuning computation into smaller, manageable units, enabling parallel processing of multiple tasks. This granular approach curtails the overall memory footprint required for finetuning while expediting the adaptation of LLMs to novel tasks sans performance compromise. Memory optimization further augments this efficiency by implementing techniques like graph pruning and dependent parallelization, thereby minimizing memory overhead associated with maintaining model states during the finetuning process.
Preliminary evaluations underscore FlexLLM’s prowess, marking a quantum leap in the domain. In scenarios characterized by intensive inference workloads, FlexLLM sustains over 80% of its peak finetuning throughput, a feat eluding existing systems. This efficiency translates into enhanced GPU utilization for both inference and finetuning operations, underscoring FlexLLM’s adeptness in navigating the resource-intensive terrain of LLMs.
Beyond its technical prowess, FlexLLM heralds a new dawn in optimizing LLM deployment, promising to democratize access and applicability across myriad domains. By substantially lowering the barriers to LLM finetuning, FlexLLM ushers in a new era of innovation and exploration, empowering a broader spectrum of stakeholders to harness the transformative potential of advanced natural language processing technologies.
Conclusion:
The introduction of FlexLLM signifies a significant advancement in the realm of AI systems. Its ability to streamline LLM finetuning and inference tasks on shared computational resources not only enhances efficiency but also opens up new avenues for market innovation. With its promise of democratizing access to advanced natural language processing technologies, FlexLLM is poised to revolutionize various sectors reliant on AI-driven solutions. Businesses should anticipate greater accessibility and efficiency in deploying LLMs, thereby driving unprecedented growth and innovation in the market.