
TL;DR:
- CMU researchers introduce MultiModal Graph Learning (MMGL) for harnessing insights from diverse multimodal connections.
- MMGL integrates machine learning, graph theory, and data fusion to handle complex data challenges.
- Applications include image caption generation, improved data retrieval, and enhanced autonomous vehicle perception.
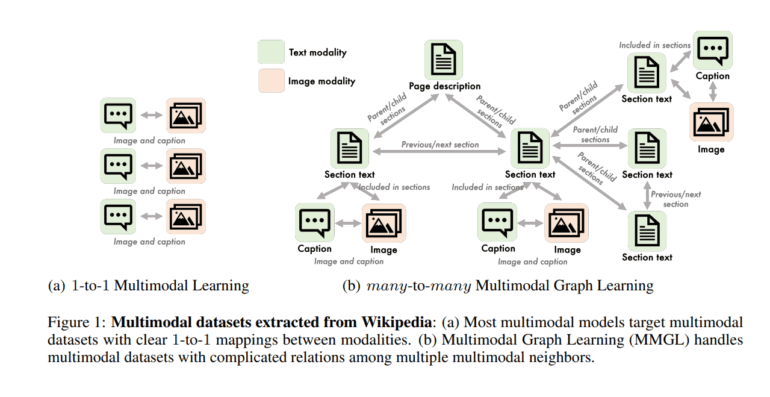
- Current AI models struggle with many-to-many mappings among data modalities.
- CMU’s systematic framework uses graph representations and parameter-efficient fine-tuning.
- They explore neighbor encoding models and cost-effective fine-tuning methods.
- MMGL paves the way for future research and application growth.
- Market implications include enhanced AI capabilities and the potential for disruptive innovations.
Main AI News:
In the realm of cutting-edge AI, a groundbreaking innovation known as MultiModal Graph Learning (MMGL) is taking the spotlight. Developed by researchers at Carnegie Mellon University, MMGL represents a pioneering approach to capturing information from a multitude of multimodal neighbors, each intertwined by complex relational structures.
Multimodal graph learning, a multidisciplinary domain that draws from the realms of machine learning, graph theory, and data fusion, addresses the formidable challenges posed by diverse data sources and their intricate interconnections. Its applications span a wide spectrum, ranging from generating descriptive captions for images by fusing visual and textual data to enhancing the precision of retrieving relevant images or text documents through advanced queries. Moreover, MMGL has found its niche in the realm of autonomous vehicles, where it harmoniously amalgamates data from an array of sensors, including cameras, LiDAR, radar, and GPS, thereby empowering these vehicles to perceive their surroundings and make informed driving decisions.
The current AI landscape largely relies on models that generate images or text from given textual descriptions or images using pre-trained image encoders and language models (LMs). These models function effectively when dealing with a clear-cut, one-to-one mapping of modalities—referring to distinct types or modes of data and information sources. However, challenges arise when the terrain shifts to the complex realm of many-to-many mappings among modalities.
Enter the Carnegie Mellon University researchers, who have unveiled a comprehensive and systematic framework for Multimodal Graph Learning tailored to generative tasks. Central to their methodology is the art of extracting valuable insights from multiple multimodal neighbors, each characterized by intricate relational structures. They achieve this by representing these multifaceted relationships as graphs, a versatile approach capable of accommodating a variable number of modalities and their intricate interplay, which can dynamically vary from one sample to the next.
The heart of their model lies in the extraction of neighbor encodings, which are then seamlessly woven together with the underlying graph structure. This synergy is further honed through parameter-efficient fine-tuning, a crucial step in maximizing the model’s performance.
To tackle the intricacies of many-to-many mappings, the research team embarked on an exploration of neighbor encoding models. This exploration included delving into self-attention with text and embeddings, self-attention with embeddings alone, and cross-attention with embedding models. To represent sequential position encodings, they employed both Laplacian eigenvector position encoding (LPE) and graph neural network encoding (GNN).
Fine-tuning, a pivotal phase in model optimization, typically necessitates a substantial amount of labeled data tailored to the specific target task. However, when an accessible dataset is already in hand or can be obtained at a reasonable cost, fine-tuning emerges as a cost-effective alternative to training a model from scratch. In this context, the researchers harnessed Prefix tuning and LoRA for Self-attention with text and embeddings (SA-TE), along with a Flamingo-style fine-tuning approach for cross-attention with embedding models (CA-E). Their findings revealed that Prefix tuning significantly reduces the number of parameters required for SA-TE neighbor encoding, effectively curbing costs.
Conclusion:
MMGL’s introduction marks a significant advancement in the field of AI and multimodal data integration. This pioneering approach has the potential to enhance AI capabilities across various industries and drive disruptive innovations in data processing and analysis. As the demand for handling complex, multimodal data continues to grow, MMGL’s systematic framework positions itself as a transformative tool in the hands of businesses and researchers alike.