
TL;DR:
- Traditional QA systems in NLP struggle with multi-document scenarios due to difficulty in extracting accurate information from structurally similar documents.
- Cornell University introduces HiQA, a novel framework that enhances document parsing and retrieval accuracy through cascading metadata and multi-route retrieval.
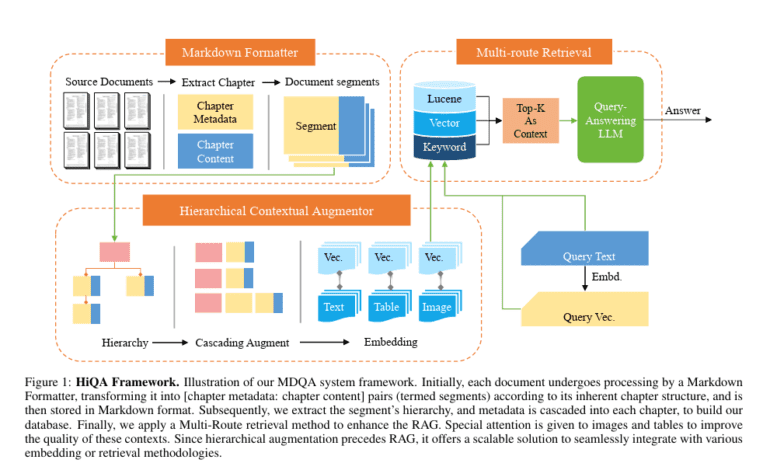
- HiQA’s methodology comprises three core components: Markdown Formatter for parsing, Hierarchical Contextual Augmentor for metadata enrichment, and Multi-Route Retriever for precise information retrieval.
- The framework excels in organizing and presenting relevant information in complex cross-document tasks, as demonstrated by its integration of cascading metadata and strategic retrieval mechanisms.
- Evaluation using the MasQA dataset and novel metrics like Log-Rank Index showcase HiQA’s effectiveness in document ranking and domain focus enhancement.
Main AI News:
Addressing the intricate challenges of multi-document question-answering (MDQA) in Natural Language Processing (NLP) stands as a formidable task. Traditional approaches often falter when confronted with vast collections of structurally homogeneous documents, struggling to extract pertinent information accurately. This issue is magnified in scenarios where the system must synthesize insights from multiple sources to formulate coherent responses.
The existing methodologies in MDQA heavily lean on Retrieval-Augmented Generation (RAG), demonstrating prowess in extracting crucial data from unstructured texts across various NLP tasks. Leveraging pre-trained models like CLIP further extends its applicability to multimodal domains such as image generation. Integrating the reasoning capabilities of Language Models (LLMs) into RAG has shown promise in discerning the need for retrieval and evaluating contextual relevance.
Notably, document QA systems like PDFTriage and PaperQA have been instrumental in structured document QA tasks by parsing structural elements and gathering evidence from pertinent papers. However, tackling multi-document QA necessitates a deeper understanding of the interrelationships between documents, often achieved through the utilization of knowledge graphs and LLMs.
Enter HiQA, a groundbreaking framework developed by researchers at Cornell University. Departing from conventional ‘hard partitioning’ techniques, HiQA adopts a ‘soft partitioning’ approach, enriching document segments with cascading metadata. This strategic maneuver enhances cohesion within the embedding space, thereby facilitating more precise knowledge retrieval in multi-document environments.
At the heart of HiQA lies three pivotal components: the Markdown Formatter (MF) for document parsing, the Hierarchical Contextual Augmentor (HCA) for metadata extraction and augmentation, and the Multi-Route Retriever (MRR) for bolstering retrieval accuracy. The MF transforms source documents into markdown files, while the HCA enriches these segments with hierarchical metadata, optimizing the information structure for retrieval. The MRR employs a sophisticated blend of vector similarity, Elastic search, and keyword matching to meticulously select the most relevant segments.
HiQA distinguishes itself in complex cross-document tasks by adeptly organizing and presenting relevant information. Its success is underpinned by the integration of cascading metadata and the strategic deployment of a multi-route retrieval mechanism. To evaluate its efficacy, the MasQA dataset comprising technical manuals, college textbooks, and public financial reports has been introduced. The Log-Rank Index emerges as a novel evaluation metric, while PCA and tSNE visualizations underscore the efficacy of HCA in enhancing the focus of the RAG algorithm on the target domain.
Conclusion:
Cornell University’s HiQA framework represents a significant advancement in the field of multi-document question-answering, offering enhanced precision and relevance in information retrieval. This innovation is poised to revolutionize various sectors reliant on efficient NLP systems, including academia, research, and information management, by streamlining complex document analysis and decision-making processes. Companies operating in these domains should monitor HiQA’s developments closely to leverage its capabilities for improved productivity and competitive advantage.