
TL;DR:
- AI’s effectiveness depends on data availability.
- Traditional belief links AI model accuracy to vast data quantities.
- University of Toronto study challenges this belief.
- Smaller, informative datasets can be as effective as large ones.
- Dr. Kangming Li’s research identifies high-quality data subsets.
- Models trained on 5% of data perform comparably to full datasets.
- Redundant data is the main issue in large datasets.
- This approach aligns with a growing trend in AI towards data quality.
Main AI News:
In today’s era of artificial intelligence, the pervasive influence of AI reverberates across every facet of our lives, revolutionizing industries and reshaping our future. Yet, at the core of AI’s prowess lies an insatiable appetite for data. The effectiveness of AI systems hinges on the availability of substantial and diverse datasets for training and development.
Traditionally, the pursuit of accuracy in training AI models has been synonymous with the sheer abundance of data. It has led us to navigate a vast and intricate landscape of potential sources, exemplified by projects like The Open Catalyst Project, which harnesses over 200 million data points related to potential catalyst materials. However, this pursuit has not been without its challenges.
The formidable computational resources demanded for the analysis and model development on such extensive datasets pose a monumental hurdle. For instance, the Open Catalyst datasets devoured a staggering 16,000 GPU days during the process of analysis and model refinement. Regrettably, such extravagant training budgets remain a luxury afforded only to select researchers, often constraining model development to smaller datasets or mere fragments of the available wealth of data.
In a groundbreaking study published in Nature Communications, researchers from the University of Toronto Engineering illuminate a path less traveled. They challenge the conventional wisdom that deep learning models necessitate copious volumes of training data. In doing so, they unveil a novel perspective that may reshape the AI landscape.
The researchers argue that the key lies not in the sheer quantity of data, but in the quest to identify smaller, yet highly informative datasets suitable for training models. Dr. Kangming Li, a postdoctoral scholar at Hattrick-Simpers, underscores this revelation by citing an example of a model designed to forecast students’ final scores. This model excels when trained on the dataset of Canadian students but falters when predicting grades for students from other countries.
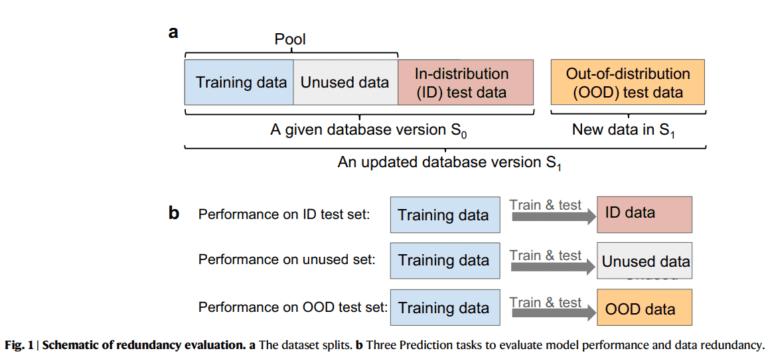
A potential remedy to this conundrum emerges in the form of identifying data subsets within colossal datasets. These subsets, while significantly more manageable, must retain the diversity and information inherent in the original dataset. Dr. Li has pioneered techniques for locating high-quality subsets of information within publicly available materials datasets such as JARVIS, The Materials Project, and Open Quantum Materials. The primary objective? To gain deeper insights into how dataset characteristics influence the models they nurture.
To achieve this, Dr. Li devised a computer program that employed the original dataset alongside a significantly smaller subset containing a mere 5% of the data points. Astonishingly, the model trained on this modest fraction performed on par with its counterpart trained on the entire dataset when predicting material properties within the dataset’s domain. This revelation underscores the astonishing fact that machine learning training can safely exclude up to 95% of the data, yielding negligible effects on the accuracy of in-distribution predictions. The culprit here is the overrepresentation of certain materials, rendering vast portions of data redundant.
In light of these findings, Dr. Li offers a methodology for assessing the redundancy of a dataset. If augmenting the dataset fails to enhance model performance, it signifies redundancy—a wealth of data that imparts no novel insights to the learning process.
This study aligns with a growing body of knowledge across various AI domains, asserting that models trained on relatively compact datasets can excel, provided the data quality remains paramount. The research ushers in a new era where quality eclipses quantity, unveiling the hidden potential within data’s intricate folds.
Conclusion:
The study reveals that the size of training datasets is not the sole determinant of AI model performance. Identifying high-quality, informative subsets within large datasets can lead to more efficient and cost-effective AI model training. This shift towards data efficiency has significant implications for the AI market, allowing businesses to optimize their resource allocation and accelerate AI development while maintaining high performance.