
TL;DR:
- DeepMind introduces AlphaStar Unplugged, a pioneering benchmark for offline reinforcement learning in the complex StarCraft II game.
- Previous AI gaming milestones were based on online RL, but StarCraft’s complexity posed a challenge.
- Offline RL leverages existing data for agent training and shows remarkable success in StarCraft II.
- Key contributions include fixed dataset training, novel evaluation metrics, and baseline agents.
- Architecture integrates modalities like vectors, units, and feature planes to achieve high performance.
- Experimental results showcase 90% win rate against top agents using only offline data.
Main AI News:
The Role of Gaming in AI Advancements
In the realm of artificial intelligence (AI), the role of video games as crucibles for testing and advancing capabilities cannot be underestimated. As AI technologies have matured, researchers have gravitated towards more intricate games that can effectively assess the multifaceted intelligence required to tackle real-world complexities. Among these, StarCraft, a Real-Time Strategy (RTS) game, stands tall as a monumental “grand challenge” for AI exploration. Its multifaceted gameplay not only pushes the frontiers of AI techniques but also mirrors the intricacies of real-world challenges.
Transcending Past Milestones
Past achievements in AI gaming, like mastering Atari, Mario, Quake III Arena Capture the Flag, and Dota 2, were largely built on online reinforcement learning (RL) strategies. However, these successes often came with constraints on game rules, the conferment of superhuman abilities, or simplified maps. StarCraft, in contrast, presents a more formidable hurdle for AI methods due to its layered complexity. While online RL algorithms have exhibited commendable success, they present challenges for applications that require minimal interaction and extensive exploration.
A Paradigm Shift: Offline Reinforcement Learning
Enter a groundbreaking paradigm shift – offline RL. This approach allows agents to glean insights and learn from pre-existing datasets, a more pragmatic and controlled method. Online RL thrives in interactive domains, whereas offline RL capitalizes on historical data, yielding deployable policies. The debut of DeepMind’s AlphaStar program, a brainchild of their researchers, marked a historic moment as it became the first AI entity to outperform a top-tier professional StarCraft player. AlphaStar achieved mastery over StarCraft II’s gameplay, powered by a deep neural network that underwent supervised and reinforcement learning using raw game data.
The Power of Data and Benchmarking
The foundation of this achievement rested upon a comprehensive repository of human player replays from StarCraft II. This invaluable resource enabled agent training and evaluation without direct environment interaction. StarCraft II’s unique challenges, such as partial observability, stochasticity, and multi-agent dynamics, rendered it an ideal testing arena to expand the boundaries of offline RL capabilities. The result? “AlphaStar Unplugged,” a benchmark meticulously tailored for intricate, partially observable games like StarCraft II, bridging the chasm between traditional online RL methodologies and the dynamic realm of offline RL.
Unlocking the Blueprint: Methodology Highlights
“AlphaStar Unplugged” is underpinned by pivotal contributions that underwrite this demanding benchmark:
- Rigorous Training Setup: A fixed dataset and defined rules ensured equitable comparisons between methods.
- Precision in Measurement: Novel evaluation metrics were introduced, enhancing the accuracy of agent performance assessment.
- Baseline Agents: A suite of finely tuned baseline agents provided solid starting points for experimental endeavors.
- Behavior Cloning Foundation: Acknowledging the intricate nature of building effective StarCraft II agents, the researchers furnished a meticulously tuned behavior cloning agent, serving as the cornerstone for all agents detailed in their paper.
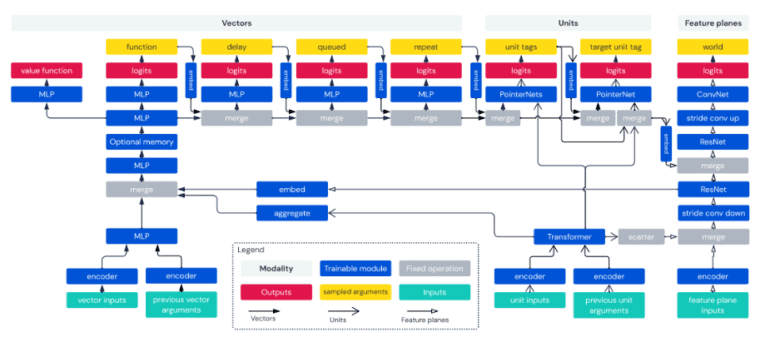
The Architecture: Weaving Modalities
The architectural framework of “AlphaStar Unplugged” revolves around reference agents for baseline comparison and metric evaluation. StarCraft II API inputs are structured into three modalities: vectors, units, and feature planes. Actions are categorized into seven modalities, encompassing function, delay, queued, repeat, unit tags, target unit tag, and world action. Multi-layer perceptrons (MLP) decode and process vector inputs, transformers manage unit inputs, and residual convolutional networks handle feature planes. These modalities are interwoven through unit scattering, vector embedding, convolutional reshaping, and memory application. The incorporation of memory into the vector modality and the utilization of a value function in tandem with action sampling further amplify the architecture’s effectiveness.
Resounding Success: Paving the Way Forward
Experimental results resoundingly underscore the triumph of offline RL algorithms, showcasing a 90% victory rate against the erstwhile leading AlphaStar Supervised agent. Remarkably, this performance is solely propelled by the utilization of offline data. The implications of this achievement are vast and transformative. The researchers anticipate that their groundbreaking work will galvanize extensive exploration in large-scale offline reinforcement learning, heralding a new era of research and applications.
A Vision Beyond: Concluding the Odyssey
In essence, DeepMind’s “AlphaStar Unplugged” introduces an unparalleled benchmark that pushes the envelope of offline reinforcement learning. By leveraging the intricate dynamics of StarCraft II, this benchmark sets the stage for elevated training methodologies and performance metrics in the expansive realm of RL research. Furthermore, it illuminates the potential of offline RL to bridge the chasm between simulated and real-world applications, offering a safer and more pragmatic path to training RL agents for the complexities of multifaceted environments. This achievement is not just a leap, but a quantum leap, propelling the AI world towards unprecedented horizons.
Conclusion:
In the rapidly evolving AI market, the advent of AlphaStar Unplugged signifies a groundbreaking leap in offline reinforcement learning. This achievement not only demonstrates the potential of offline RL in mastering intricate games but also hints at the broader applications of safer and more practical agent training methodologies. The success of AlphaStar Unplugged paves the way for advancements in various industries where AI-powered decision-making and optimization play a pivotal role, promising more capable and sophisticated AI systems that can navigate complex real-world challenges with greater precision and efficiency.