
- DeepSeek-VL is an open-source Vision Language (VL) Model designed by DeepSeek-AI.
- It bridges the gap between visual and linguistic realms in artificial intelligence.
- The model’s nuanced data construction approach ensures diversity and richness in datasets.
- DeepSeek-VL features a sophisticated hybrid vision encoder for processing high-resolution images efficiently.
- It demonstrates exceptional performance in comprehending and interacting with visual and textual data.
- DeepSeek-VL sets a new standard in vision-language understanding with its superior multimodal comprehension.
Main AI News:
The convergence of visual and linguistic realms stands as a pivotal frontier in the dynamic landscape of artificial intelligence. This fusion, epitomized by vision-language models, endeavors to unravel the intricate correlation between imagery and textual content. These advancements bear immense significance across numerous sectors, from augmenting accessibility to furnishing automated support across diverse industries.
The pursuit of models proficient in navigating the multifaceted nuances of real-world visuals and textual data presents formidable challenges. These hurdles encompass the imperative for models to discern, interpret, and contextualize visual input within the subtleties of natural language. Despite notable strides, existing solutions often necessitate refinement in terms of data comprehensiveness, processing efficiency, and seamless integration of visual and linguistic elements.
DeepSeek-AI researchers have proudly introduced DeepSeek-VL, an innovative open-source Vision Language (VL) Model. This endeavor underscores DeepSeek-AI’s pioneering ethos, marking a significant advancement in the realm of vision-language modeling. The advent of DeepSeek-VL signals a paradigm shift, offering groundbreaking solutions to longstanding impediments within the discipline.
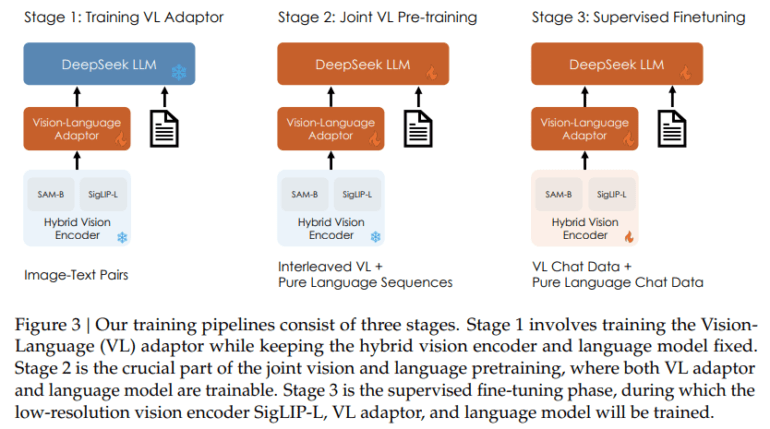
Central to DeepSeek-VL’s success is its meticulous approach to data curation. The model draws upon a myriad of real-world scenarios, ensuring a diverse and robust dataset. This diverse foundation proves instrumental, empowering the model to tackle an array of tasks with exceptional efficacy and precision. Such inclusivity in data sourcing enables DeepSeek-VL to adeptly navigate and interpret the intricate interplay between visual stimuli and textual narratives.
DeepSeek-VL further distinguishes itself through its sophisticated model architecture. Featuring a hybrid vision encoder capable of processing high-resolution images within manageable computational constraints, it signifies a significant leap in overcoming prevalent bottlenecks. This architectural innovation enables detailed analysis of visual data, empowering DeepSeek-VL to excel across diverse visual tasks without compromising processing speed or accuracy. This strategic architectural decision underscores the model’s capacity to deliver unparalleled performance, propelling advancements in the vision-language comprehension domain.
The effectiveness of DeepSeek-VL is evident through rigorous performance evaluations. Demonstrating exceptional prowess in comprehending and interacting with the visual and textual realms, DeepSeek-VL sets a new benchmark in these assessments. Achieving state-of-the-art or competitive performance across various benchmarks, the model strikes a robust equilibrium between language comprehension and vision-language tasks. This equilibrium underscores DeepSeek-VL’s unmatched multimodal understanding, setting a new standard in the discipline.
Conclusion:
The introduction of DeepSeek-VL signifies a significant advancement in the field of vision-language understanding. Its innovative approach to data construction and sophisticated model architecture promise groundbreaking solutions for real-world applications. This development opens up new opportunities for industries reliant on AI-driven vision and language processing, fostering enhanced accessibility and automated assistance. DeepSeek-VL sets a new benchmark, driving competition and innovation in the market for vision-language models.