
TL;DR:
- DeepSpeed-FastGen is introduced to enhance efficiency in serving Large Language Models (LLMs).
- The system addresses the challenge of balancing high throughput and low latency in LLM serving.
- Traditional LLM serving approaches struggle with open-ended text generation due to poor arithmetic intensity.
- DeepSpeed-FastGen employs the Dynamic SplitFuse strategy to decompose long prompts for better efficiency.
- It achieves up to 2.3x higher effective throughput and 2x lower latency on average compared to existing systems.
- DeepSpeed-FastGen supports various LLM models and offers flexible deployment options.
- The system’s performance was rigorously benchmarked and outperformed vLLM in multiple scenarios.
Main AI News:
In the ever-evolving landscape of artificial intelligence, Large Language Models (LLMs) have undeniably played a pivotal role in revolutionizing diverse applications, ranging from conversational agents to autonomous driving systems. As the demand for handling extended prompts and workloads continues to surge, the critical challenge at hand is to strike a harmonious balance between high throughput and minimal latency in LLM serving systems. Existing frameworks grapple with this challenge, beckoning for innovative solutions.
Traditional methods of LLM serving excel in model training but often falter during inference, particularly in tasks like open-ended text generation. The inherent inefficiency in these approaches arises from the interactive nature of such applications and the inherent lack of computational intensity in these tasks, which can act as bottlenecks hindering the inference throughput in existing systems. While solutions like vLLM, fortified by PagedAttention, and research systems like Orca have made strides in enhancing LLM inference performance, they still confront difficulties in ensuring consistent quality of service, especially for prolonged prompt workloads.
Historical advancements in LLM inference, such as blocked KV caching and dynamic batching, have aimed to address memory efficiency and GPU utilization. Blocked KV caching, as witnessed in vLLM’s Paged Attention, effectively tackled memory fragmentation concerns linked to large KV caches, thereby augmenting the overall system throughput. However, dynamic batching, despite its innovation, occasionally necessitated input padding or system stalling to form larger batches, thus posing limitations in efficiently serving LLMs, particularly when dealing with extended prompt workloads.
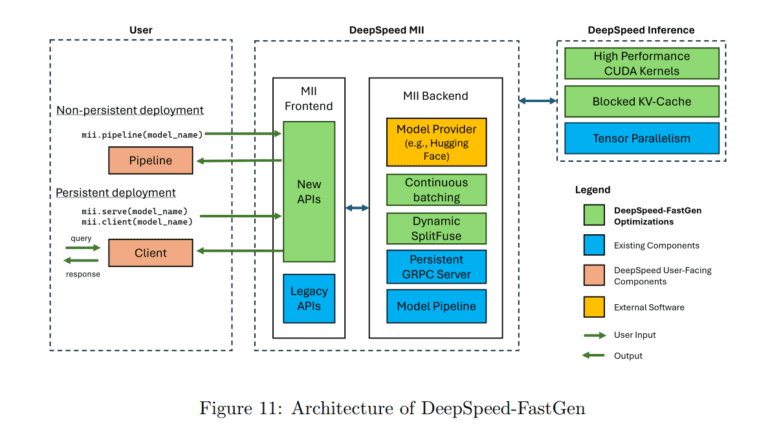
In response to these formidable challenges, the Microsoft DeepSpeed research team has introduced DeepSpeed-FastGen. This groundbreaking system leverages the Dynamic SplitFuse technique, promising to usher in a new era of LLM serving efficiency. DeepSpeed-FastGen, the amalgamation of DeepSpeed-MII and DeepSpeed-Inference, emerges as an efficient, user-friendly serving solution for LLMs, catering to a wide array of models and offering both non-persistent and persistent deployment options, adaptable to various user scenarios.
At the heart of DeepSpeed-FastGen’s unrivaled efficiency lies the Dynamic SplitFuse strategy, which enhances continuous batching and overall system throughput. This pioneering token composition strategy for prompt processing and generation breaks down lengthy prompts into smaller, manageable chunks across multiple forward passes. This approach not only ensures improved system responsiveness but also significantly enhances efficiency, eliminating the need for excessively long forward passes associated with extended prompts. The consistency in forward pass sizes, a key determinant of performance, leads to more predictable latency compared to competing systems, resulting in substantial reductions in generation latency, as corroborated by rigorous performance evaluations.
DeepSpeed-FastGen’s prowess was subjected to comprehensive benchmarking and analysis, where it outshone vLLM across various models and hardware configurations. The results were unequivocal – DeepSpeed-FastGen achieved up to 2.3x higher effective throughput, maintained an average latency that was 2x lower, and exhibited up to 3.7x lower tail latency when compared to vLLM. These enhancements bear immense significance in the realm of LLM serving, where the fusion of superior throughput and reduced latency serves as the hallmark of excellence.
Conclusion:
The introduction of DeepSpeed-FastGen represents a significant leap forward in the AI market, as it addresses a critical challenge in efficiently serving Large Language Models. By enhancing throughput and reducing latency, it empowers businesses and AI applications to deliver more responsive and efficient services, opening up new possibilities for innovation and improved user experiences in various industries.