
TL;DR:
- Video segmentation is essential for identifying objects and events in videos.
- Traditional methods require extensive data labeling, making them costly and inflexible.
- DEVA (Decoupled Video Segmentation) introduces a two-part approach: frame-specific object identification and universal temporal analysis.
- DEVA reduces the need for task-specific training data, saving costs and enhancing adaptability.
- The bi-directional propagation technique ensures consistent results in real-time scenarios.
- External task-agnostic data enhances generalization, particularly for data-scarce tasks.
- DEVA, when paired with universal image segmentation models, achieves cutting-edge performance.
Main AI News:
Have you ever marveled at the intricate workings of surveillance systems, their ability to discern individuals or vehicles from mere video footage, or the process of identifying an orca in the depths of underwater documentaries? Perhaps you’ve contemplated the magic behind live sports analysis. All these feats are made possible through video segmentation, a pivotal process that dissects videos into multiple regions, guided by distinct characteristics like object boundaries, motion, color, texture, and other visual cues. At its core, video segmentation aims to distinguish and isolate diverse objects and temporal events within a video, offering a comprehensive and structured portrayal of its visual content.
Expanding the horizons of video segmentation algorithms has historically come at a steep price, demanding copious amounts of labeled data. The need for training algorithms for each unique task has hindered progress. However, a groundbreaking solution has emerged in the form of Decoupled Video Segmentation, or DEVA. DEVA comprises two integral components: one tailored for pinpointing objects within individual frames and another that masterfully bridges temporal gaps, irrespective of the nature of the objects in question. This ingenious approach renders DEVA adaptable and versatile across a spectrum of video segmentation tasks, obviating the necessity for extensive training datasets.
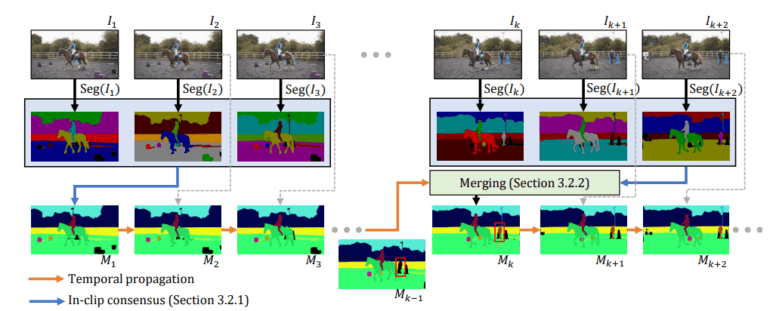
This innovative design facilitates the use of a simpler image-level model for the specific task at hand, one that is far more cost-effective to train. Concurrently, a universal temporal propagation model enters the fray, requiring only a single training session yet capable of serving multiple purposes. The synergy between these two modules is orchestrated through a bi-directional propagation methodology, ensuring the cohesion and consistency of the final segmentation outcome, even in real-time or online scenarios.
The diagram above provides a glimpse into the framework’s mechanics. The research team initiates the process by sifting through image-level segmentations, applying in-clip consensus, and advancing this result temporally. When confronted with new image segments at subsequent time steps, such as the emergence of previously unseen objects (e.g., a red box), they seamlessly integrate the propagated results with the in-clip consensus.
This research employs a strategy heavily reliant on external task-agnostic data, strategically aimed at reducing dependence on specific target tasks. The payoff is evident in its superior generalization capabilities, particularly beneficial for tasks constrained by limited available data compared to conventional end-to-end approaches. Remarkably, it circumvents the need for intricate fine-tuning. When coupled with universal image segmentation models, this decoupled paradigm stands as a testament to cutting-edge performance, marking a significant stride towards achieving state-of-the-art large-vocabulary video segmentation within an open-world context.
Conclusion:
DEVA’s innovative approach to video segmentation not only reduces the cost and complexity of training but also enhances versatility and performance. This breakthrough has the potential to reshape the market for video analysis and segmentation solutions, making them more accessible and adaptable to a wide range of industries and applications. Businesses should consider incorporating DEVA into their video processing workflows to stay at the forefront of this transformative technology.