
TL;DR:
- Salesforce AI and Columbia University introduce DialogStudio, a comprehensive collection of 80 diverse dialogue datasets.
- It enables human-like interactions between machines and users in conversational AI.
- DialogStudio aggregates 33 distinct datasets covering various domains and dialogue types.
- A dialogue quality assessment framework ensures dataset quality for effective model performance.
- Researchers gain convenient access to datasets through HuggingFace, streamlining development and evaluation.
- DialogStudio offers version 1.0 of models, providing a solid starting point for sophisticated AI systems.
Main AI News:
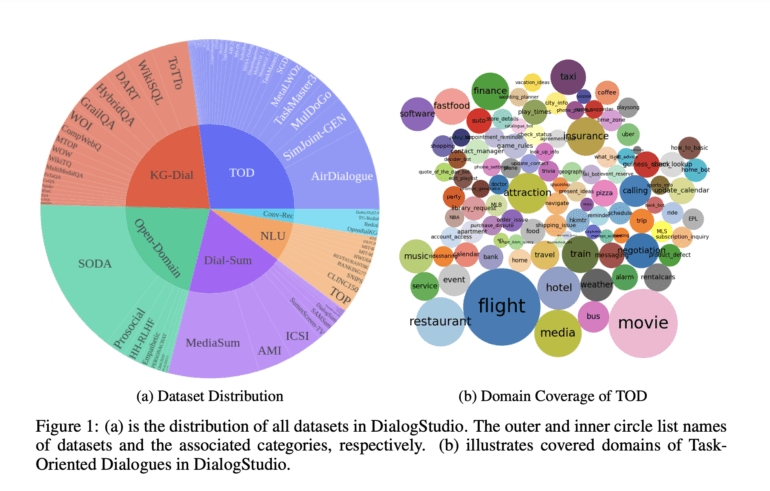
Researchers from Salesforce AI and Columbia University have joined forces to introduce a groundbreaking initiative known as DialogStudio, which presents a comprehensive collection of 80 diverse dialogue datasets. These datasets serve as a pivotal element in the advancement of conversational AI, enabling machine-human interactions that closely mimic human-like conversations. The availability of such extensive and varied datasets has been a key driving force behind the remarkable progress in developing sophisticated language models.
In the realm of conversational AI, having access to a diverse range of datasets covering various domains and dialogue types is paramount. Traditionally, different research groups have contributed datasets tailored to specific conversational scenarios. However, this scattered approach has highlighted the need for standardization and interoperability among datasets, making it challenging to compare and integrate them effectively.
DialogStudio addresses this crucial issue by consolidating 33 distinct datasets, each representing different categories like Knowledge-Grounded Dialogues, Natural-Language Understanding, Open-Domain Dialogues, Task-Oriented Dialogues, Dialogue Summarization, and Conversational Recommendation Dialogs. Through a meticulous unification process, DialogStudio ensures that the original information from each dataset is retained while facilitating seamless integration and cross-domain research.
Ensuring the quality and suitability of the datasets for various applications is a top priority for DialogStudio. To achieve this, the initiative adopts a comprehensive dialogue quality assessment framework. Dialogues are evaluated based on six critical criteria: Understanding, Relevance, Correctness, Coherence, Completeness, and Overall Quality. This assessment allows researchers and developers to effectively gauge the performance of their models, with scores assigned on a scale of 1 to 5, indicating the quality of the dialogues.
DialogStudio ensures convenient access to its vast collection of datasets through HuggingFace, a widely-used platform for natural language processing resources. By claiming the dataset name corresponding to the dataset folder name within DialogStudio, researchers can swiftly load any dataset. This streamlined process accelerates the development and evaluation of conversational AI models, saving valuable time and effort.
It is essential to note that DialogStudio currently offers version 1.0 of models trained on select datasets. While these models are based on small-scale pre-trained models and do not incorporate large-scale datasets like Alpaca, ShareGPT, GPT4ALL, UltraChat, or other datasets such as OASST1 and WizardCoder, they serve as a solid starting point for developing sophisticated AI systems.
Conclusion:
DialogStudio’s introduction marks a significant milestone in the conversational AI market. With its unified and extensive collection of diverse dialogue datasets, it empowers researchers and developers to push the boundaries of AI interactions, resulting in more sophisticated and human-like conversations between machines and users. The convenient access to datasets and the comprehensive quality assessment framework further contribute to the acceleration of AI model development and evaluation, driving the market towards enhanced conversational AI solutions.