

TL;DR:
- DiffusionGPT, developed by ByteDance and Sun Yat-Sen University, introduces a unified text-to-image generation framework.
- It leverages a Large Language Model (LLM) and a Tree-of-Thought (ToT) structure to integrate diverse generative models.
- The system excels at parsing prompts, model selection, and execution of generation, culminating in enhanced output quality.
- Human feedback, facilitated by Advantage Databases, aligns model selection with user preferences.
- ChatGPT serves as the LLM controller within the LangChain framework, providing precise guidance.
- DiffusionGPT outperforms baseline models, addressing semantic limitations and enhancing image aesthetics.
- This innovation has significant implications for industries where text and images converge.
Main AI News:
In the realm of image generation, diffusion models have marked a remarkable stride, bringing forth top-tier models that are readily available on open-source platforms. Nevertheless, the domain of text-to-image systems faces persistent challenges, especially in accommodating a wide array of inputs and breaking free from the confines of single-model outcomes. Addressing these challenges involves concerted efforts aimed at two distinct aspects: first, the intricate parsing of diverse prompts during the input stage, and second, the skillful activation of expert models for the generation of output.
Recent years have witnessed the ascendancy of diffusion models like DALLE-2 and Imagen, revolutionizing image editing and stylization. However, their non-open source nature has hindered their widespread adoption. Enter Stable Diffusion (SD), an open-source text-to-image model, along with its latest iteration, SDXL, both of which have garnered substantial popularity. Nonetheless, challenges stemming from model limitations and prompt constraints persist, albeit with innovative solutions like SD1.5+Lora and prompt engineering. Despite these strides, the pursuit of optimal performance remains ongoing. The question that lingers is this: Can a unified framework be devised to surmount prompt constraints and activate domain expert models effectively?
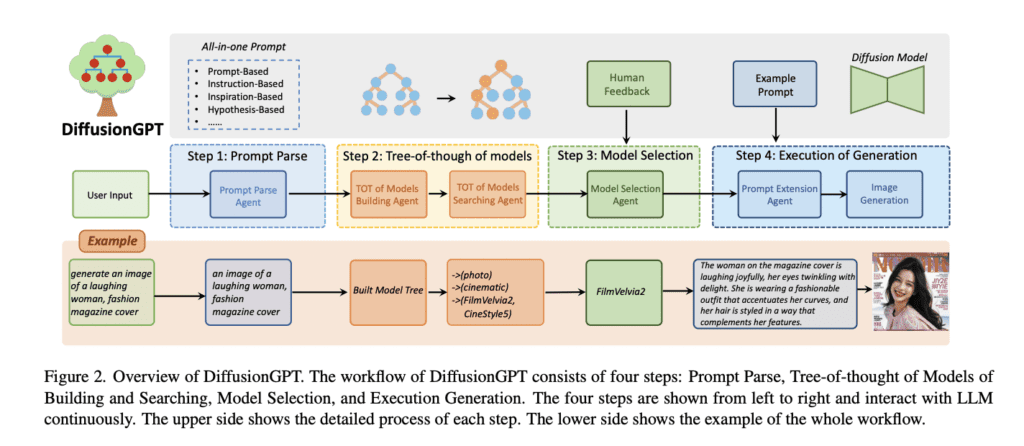
Researchers from ByteDance and Sun Yat-Sen University have introduced DiffusionGPT, a groundbreaking approach harnessing the power of a Large Language Model (LLM) to create an all-encompassing generation system. Employing a structured Tree-of-Thought (ToT), this system seamlessly integrates various generative models, drawing upon prior knowledge and human feedback. The LLM adeptly parses prompts and guides the ToT in selecting the most suitable model for generating the desired output. Moreover, Advantage Databases enrich the ToT with valuable human feedback, aligning the model selection process with human preferences, thereby furnishing a comprehensive and user-informed solution.
Source: Marktechpost Media Inc.
The DiffusionGPT system follows a meticulously designed four-step workflow:
- Prompt Parse: This initial stage involves the extraction of salient information from a diverse array of prompts.
- Tree-of-Thought of Models Build and Search: A hierarchical model tree is constructed to facilitate efficient searching and selection.
- Model Selection with Human Feedback: Human feedback, harnessed through Advantage Databases, plays a pivotal role in ensuring alignment with user preferences.
- Execution of Generation: Finally, the chosen generative model undergoes the execution of generation, with the assistance of a Prompt Extension Agent dedicated to enhancing prompt quality for superior outputs.
Notably, researchers have enlisted ChatGPT as the LLM controller within their experimental setup, seamlessly integrating it into the LangChain framework to provide precise guidance. The results were nothing short of impressive, with DiffusionGPT showcasing superior performance when compared to baseline models such as SD1.5 and SD XL across various types of prompts. Noteworthy achievements include addressing semantic limitations and elevating image aesthetics, as DiffusionGPT outperformed SD1.5 in both image-reward and aesthetic scores by a notable 0.35% and 0.44%, respectively.

Source: Marktechpost Media Inc.
Conclusion:
The introduction of DiffusionGPT represents a significant leap forward in the field of text-to-image generation. This innovative system, driven by a Large Language Model and human feedback, promises to revolutionize content creation and image generation across various business sectors. It opens up new possibilities for businesses seeking to enhance their visual content and creativity, ultimately leading to improved engagement and user satisfaction in a competitive market landscape.