
TL;DR:
- DiLoCo is Google DeepMind’s innovative low-communication algorithm for large language model training.
- It reduces communication overhead by 500 times while achieving remarkable performance.
- Inspired by Federated Learning, DiLoCo blends FedAvg and FedOpt algorithms, incorporating AdamW and Nesterov Momentum.
- Key pillars include limited co-location requirements, reduced communication frequency, and device heterogeneity.
- The training process involves replicating and updating model replicas across multiple devices.
- DiLoCo performs exceptionally well on the C4 dataset, adapting to varying data distributions and resource availabilities.
Main AI News:
The remarkable progress of language models in practical applications often faces formidable obstacles during their extensive training using conventional techniques such as standard backpropagation. Google DeepMind has unveiled a groundbreaking solution with DiLoCo (Distributed Low-Communication), setting a new standard for optimizing language models. In their paper titled “DiLoCo: Distributed Low-Communication Training of Language Models,” the research team introduces an innovative distributed optimization algorithm that operates on loosely connected device clusters. This pioneering approach delivers a remarkable performance boost while reducing communication overhead by an impressive 500-fold.
Taking inspiration from Federated Learning principles, the researchers have ingeniously modified the widely recognized Federated Averaging (FedAvg) algorithm, infusing it with elements reminiscent of the FedOpt algorithm. DiLoCo strategically incorporates AdamW as the inner optimizer and leverages Nesterov Momentum as the outer optimizer. This fusion of techniques addresses the challenges inherent in traditional training methods, resulting in a transformative approach.
DiLoCo’s brilliance can be attributed to its three fundamental pillars:
- Limited Co-location Requirements: Each worker requires co-located devices, but the total number needed is significantly reduced, simplifying logistical complexities.
- Reduced Communication Frequency: Workers no longer need constant communication but synchronize only at intervals of 𝐻 steps, drastically reducing communication overhead to mere hundreds or even thousands.
- Device Heterogeneity: While devices within a cluster must be homogeneous, DiLoCo permits different clusters to operate using diverse device types, providing unmatched flexibility.
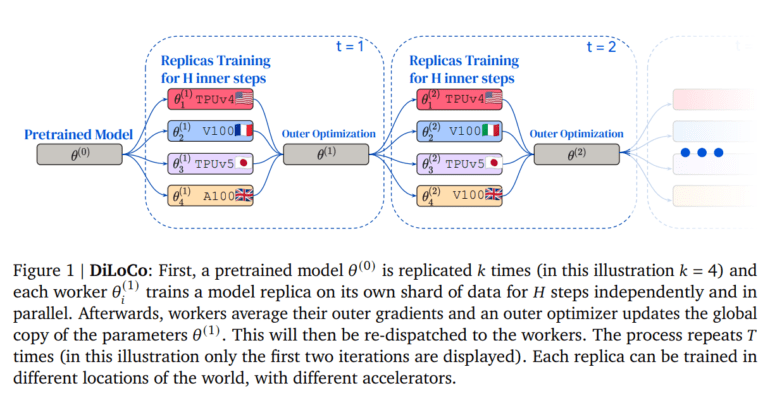
The DiLoCo training process involves replicating a pretrained model (0) multiple times. Each worker independently trains a model replica on its individual data shard for 𝐻 steps. Subsequently, workers average their outer gradients, and an outer optimizer updates the global parameter copy (1), which is then distributed back to the workers. This cyclical process repeats 𝑇 times, enabling each replica’s training in distinct global locations using various accelerators.
In practical experiments conducted with the C4 dataset, DiLoCo, with eight workers, achieves performance on par with fully synchronous optimization while reducing communication overhead by an astounding 500 times. Furthermore, DiLoCo demonstrates exceptional resilience when faced with variations in data distribution among workers and seamlessly adapts to changing resource availabilities during training.
Conclusion:
DiLoCo’s game-changing approach to language model training offers businesses a competitive edge. By significantly reducing communication overhead and increasing adaptability, it opens doors to more efficient and resilient AI applications, creating new opportunities for market growth and innovation.