
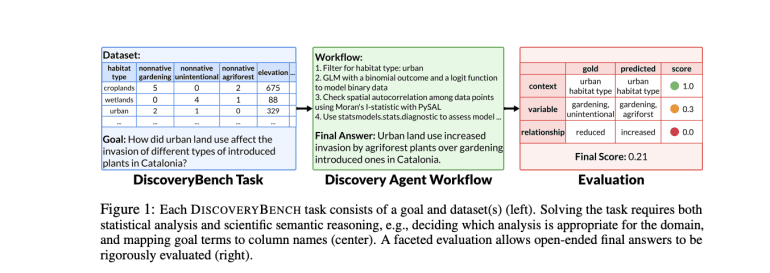
- DiscoveryBench introduces a benchmark for large language models (LLMs) to automate data-driven scientific discovery.
- It formalizes tasks to explore relationships between variables across diverse domains.
- The benchmark integrates scientific semantic reasoning, aiding in domain-specific analysis and hypothesis verification.
- It includes DB-REAL for real-world hypotheses and workflows, and DB-SYNTH for synthetic benchmarks.
- Evaluation shows varying performance among LLM-powered agents, with Reflexion (Oracle) demonstrating notable adaptability.
Main AI News:
In the realm of scientific advancement, the evolution of large language models (LLMs) has introduced new dimensions to autonomous discovery systems. These systems aim to revolutionize scientific processes by autonomously generating and verifying hypotheses, leveraging advanced reasoning capabilities and interaction with external tools. Despite promising initial results, the full potential of LLMs in scientific discovery remains uncertain, prompting researchers to explore and enhance these AI systems further.
Historically, automated data-driven discovery efforts have evolved from early systems like Bacon to contemporary solutions such as AlphaFold, each addressing specific datasets and pipelines. However, existing tools like AutoML platforms and statistical analysis software, while valuable for model training and data analysis, lack comprehensive capabilities for open-ended discovery tasks. The QRData dataset exemplifies progress in statistical and causal analysis within well-defined parameters but falls short in addressing broader discovery processes encompassing ideation, semantic reasoning, and pipeline design.
Enter DISCOVERYBENCH, a collaborative effort by the Allen Institute for AI, OpenLocus, and the University of Massachusetts Amherst. This benchmark sets out to systematically evaluate state-of-the-art LLMs in automated data-driven discovery across diverse real-world domains. It introduces a pragmatic formalization that defines discovery tasks as the exploration of relationships between variables within specific contexts, transcending direct dataset language constraints. This structured approach ensures reproducible evaluations of complex real-world problems, marking a significant leap forward in the evaluation of AI-driven discovery systems.
Unique to DISCOVERYBENCH is its integration of scientific semantic reasoning, encompassing domain-specific analysis techniques, data normalization, and alignment of goal terms with dataset variables. Unlike previous datasets focused on AutoML or statistical analysis, DISCOVERYBENCH adopts a multistep workflow approach that mirrors the comprehensive nature of data-driven discovery pipelines. This holistic framework positions DISCOVERYBENCH as the pioneering large-scale dataset dedicated to exploring the complete spectrum of LLM capabilities in scientific discovery.
Central to DISCOVERYBENCH is its dual-component structure: DB-REAL and DB-SYNTH. DB-REAL comprises real-world hypotheses and workflows sourced from diverse scientific disciplines, demanding nuanced dataset analysis and advanced statistical modeling. In contrast, DB-SYNTH generates synthetic benchmarks that enable controlled evaluations of LLMs across varying difficulty levels. This dual approach not only reflects the complexity of real-world discovery challenges but also facilitates rigorous model assessment under controlled conditions.
The study evaluates multiple discovery agents powered by leading LLMs, including GPT-4o, GPT-4p, and Llama-3-70B, using the DISCOVERYBENCH dataset. Agents like CodeGen, ReAct, DataVoyager, Reflexion (Oracle), and NoDataGuess undergo rigorous testing across both DB-REAL and DB-SYNTH components. Results reveal that while advanced reasoning models show potential, performance across agent-LLM pairs remains challenging. Notably, Reflexion (Oracle) demonstrates superior adaptability and performance improvement capabilities compared to simpler agents like CodeGen, underscoring the benchmark’s effectiveness in capturing real-world complexities.
This comprehensive evaluation highlights DISCOVERYBENCH as a pivotal resource in advancing the capabilities of LLMs in scientific discovery, promising accelerated innovation across diverse fields through autonomous and systematic data-driven exploration.
Conclusion:
The introduction of DiscoveryBench marks a significant advancement in automating scientific discovery through LLMs. By formalizing and standardizing the evaluation of these models across real-world and synthetic datasets, it sets a new benchmark for the industry. This development not only enhances the efficiency of data-driven discovery processes but also underscores the potential for accelerated innovation across scientific disciplines. As LLM capabilities continue to evolve, businesses and research institutions leveraging these technologies stand to gain competitive advantages in driving forward scientific knowledge and breakthroughs.