
TL;DR:
- DreamDiffusion introduces a breakthrough model for generating high-quality images directly from brain EEG signals.
- It leverages pre-trained text-to-image diffusion models and addresses challenges specific to EEG signals.
- The method explores the temporal aspects of EEG signals, overcomes noise and limited data challenges, and aligns EEG, text, and image spaces.
- DreamDiffusion has significant potential for efficient artistic creation, dream visualization, and therapeutic applications.
- It provides a low-cost alternative to fMRI-based methods and enables accessible image generation from brain activity.
Main AI News:
In recent years, the field of image generation from brain activity has experienced remarkable progress, thanks to groundbreaking advancements in text-to-image conversion. However, the challenge of translating thoughts into images using brain electroencephalogram (EEG) signals has remained an enigma. DreamDiffusion, a cutting-edge model, aims to bridge this gap by leveraging pre-trained text-to-image diffusion models to produce realistic and high-quality images based solely on EEG signals. This innovative method delves into the temporal intricacies of EEG signals, tackles noise and limited data challenges, and seamlessly aligns EEG, text, and image domains. The advent of DreamDiffusion paves the way for efficient artistic creation, dream visualization, and potential therapeutic applications for individuals with autism or language disabilities.
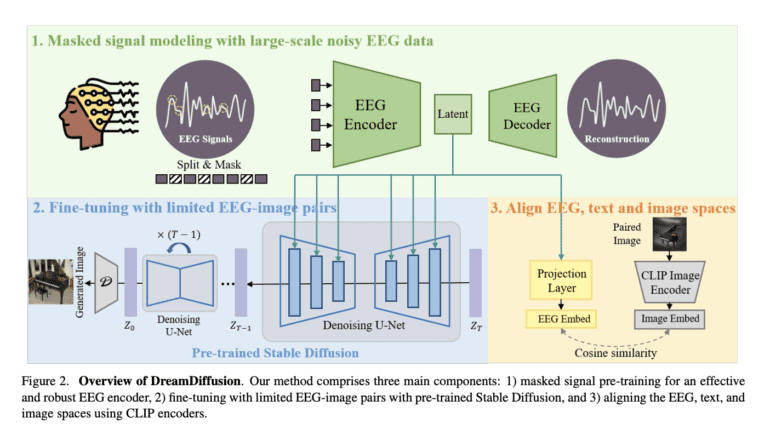
Prior research endeavors have explored image generation from brain activity, employing techniques such as functional Magnetic Resonance Imaging (fMRI) and EEG signals. While fMRI-based methods necessitate expensive and non-portable equipment, EEG signals offer a more accessible and cost-effective alternative. Building upon existing fMRI-based approaches, such as MinD-Vis, DreamDiffusion harnesses the power of pre-trained text-to-image diffusion models. This groundbreaking model surmounts challenges specific to EEG signals by employing masked signal modeling for EEG encoder pre-training and utilizing the CLIP image encoder to align EEG, text, and image spaces flawlessly.
The DreamDiffusion framework comprises three key components: masked signal pre-training, fine-tuning with limited EEG-image pairs using pre-trained Stable Diffusion, and alignment of EEG, text, and image spaces using CLIP encoders. By employing masked signal modeling, the EEG encoder undergoes pre-training, allowing for effective and robust EEG representations through the reconstruction of masked tokens based on contextual cues. Additionally, the integration of the CLIP image encoder refines EEG embeddings and aligns them with CLIP text and image embeddings. As a result, the generated EEG embeddings facilitate image generation with enhanced quality.
Despite its remarkable achievements, DreamDiffusion does possess certain limitations that merit acknowledgment. One significant limitation lies in the fact that EEG data only provide coarse-grained information at the category level. Some instances have exhibited cases where certain categories were erroneously mapped to others due to similarities in shapes or colors. This discrepancy arises from the human brain’s emphasis on shape and color as crucial factors in object recognition.
Notwithstanding these limitations, DreamDiffusion holds immense potential for various applications in neuroscience, psychology, and human-computer interaction. The capability to generate high-quality images directly from EEG signals opens up new avenues for research and practical implementations in these fields. With further advancements, DreamDiffusion can transcend its limitations and contribute to a wide range of interdisciplinary areas. Researchers and enthusiasts interested in exploring and developing this exciting field can access the DreamDiffusion source code on GitHub, facilitating further exploration and advancement in this revolutionary domain.
Conclusion:
DreamDiffusion’s ability to generate high-quality images directly from brain EEG signals has immense implications for the market. It opens up new opportunities in neuroscience, psychology, and human-computer interaction, allowing for advancements in research and practical implementations. With its low-cost and accessible approach compared to fMRI-based methods, DreamDiffusion has the potential to revolutionize the field and attract interest from various industries, including healthcare, entertainment, and technology. Its capabilities in efficient artistic creation and potential therapeutic applications for individuals with autism or language disabilities further contribute to its market value. The availability of the DreamDiffusion source code on GitHub facilitates collaboration, exploration, and development in this exciting field, fostering innovation and growth.