
TL;DR:
- Dense retrieval models are critical for enterprise search and personalized customer service.
- Existing models are time-consuming, costly, and hinder rapid adaptation.
- DREditor, by Sichuan University, introduces a time-efficient approach using linear mapping.
- It achieves 100-300 times faster efficiency while maintaining or surpassing retrieval performance.
- DREditor reduces customization time and enhances generalization capacity.
- Market implications: DREditor promises cost-effective, efficient domain-specific retrieval models, reshaping the industry.
Main AI News:
Deploying state-of-the-art dense retrieval models has become a cornerstone of success in industries like enterprise search (ES), particularly when catering to multiple enterprises with unique needs. In the realm of ES, think of Cloud Customer Service (CCS), where the ability to swiftly generate personalized search engines from uploaded business documents can make or break customer satisfaction. The key to success for ES providers lies in their ability to deliver time-efficient customization, ensuring scalability without compromising on user experience or incurring unnecessary business losses.
Yet, the existing models, often reliant on protracted fine-tuning procedures, fall short in addressing the urgency and resource constraints faced by modern businesses. Extended training times drain computational resources, inflating infrastructure costs and energy consumption. Moreover, they inhibit the nimble adaptation necessary to stay ahead in dynamic markets. Clearly, a novel solution is imperative.
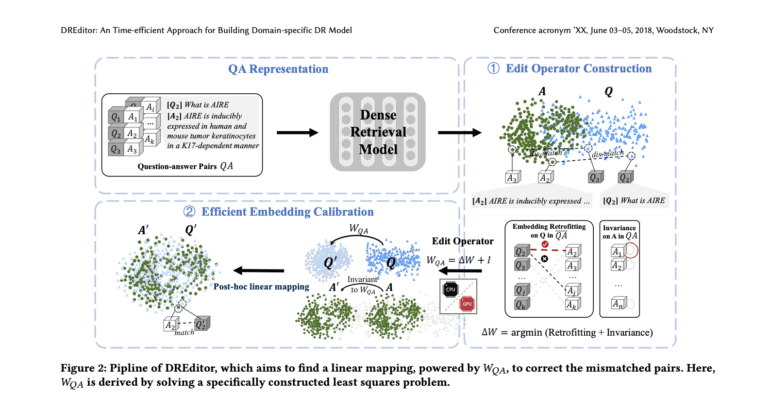
Enter DREditor, a groundbreaking innovation from the research labs of the College of Computer Science at Sichuan University and the Engineering Research Center of Machine Learning and Industry Intelligence, Ministry of Education Chengdu, China. DREditor presents a time-efficient paradigm for tailoring off-the-shelf dense retrieval models to specific domains. Through the implementation of an efficient linear mapping technique, DREditor recalibrates output embeddings by solving a carefully devised least squares problem, all through a specially constructed edit operator.
In stark contrast to the cumbersome fine-tuning processes of the past, DREditor sets a new standard for speed and efficiency. Experimental evidence unequivocally showcases that DREditor achieves a mind-boggling 100-300 times increase in efficiency across various datasets, sources, models, and devices, all while either maintaining or surpassing retrieval performance benchmarks.
DREditor leverages adapter fine-tuning and introduces a streamlined approach by directly calibrating output embeddings using the power of linear mapping. It efficiently tackles the challenge of customization, promoting the generalization capacity of dense retrieval models across diverse domains. The pivotal post-processing stage of DREditor revolves around a computation-efficient linear transformation, fueled by the derived edit operator𝑊𝑄𝐴.
The profound advantages of DREditor in terms of time efficiency cannot be overstated. With a staggering 100-300 times reduction in customization time compared to traditional fine-tuning methods, it not only outperforms implicit rule modification techniques but also underscores its prowess across diverse datasets, sources, retrieval models, and computing devices. DREditor bridges the technical gap in embedding calibration, ushering in an era of cost-effective and efficient development of domain-specific dense retrieval models.
Conclusion:
The introduction of DREditor represents a significant leap forward in the world of enterprise search. By dramatically reducing customization time while maintaining or improving retrieval performance, this innovation promises to revolutionize the market. Businesses can now offer tailored solutions more efficiently, saving time and resources, and ultimately delivering superior customer experiences. DREditor sets the stage for a new era of domain-specific retrieval models, making the market more competitive and agile than ever before.