
TL;DR:
- LVLMs like DRESS combine large language models with visual instruction for user-friendly responses.
- Challenges persist in aligning LVLM responses with human preferences.
- Weak connections between conversational turns hinder LVLM interaction.
- DRESS introduces Natural Language Feedback (NLF) to fine-tune responses.
- NLF is classified into critique and refinement, enhancing LVLMs’ interaction capabilities.
- Conditional reinforcement learning techniques are employed for training DRESS.
- DRESS excels in multi-turn interactions, harmlessness, honesty, and helpfulness evaluations.
- This approach marks a significant step in addressing LVLM interaction and the 3H criteria.
Main AI News:
In the realm of cutting-edge vision-language models, a groundbreaking development is taking place with the introduction of ‘DRESS’: a Large Vision Language Model (LVLM) that stands at the forefront of human interaction through natural language feedback. LVLMs, which are proficient at deciphering visual cues and delivering user-friendly responses, achieve this feat by skillfully amalgamating large language models (LLMs) with extensive visual instruction fine-tuning. However, the journey to perfection is far from over, as LVLMs still grapple with the production of responses that can be hurtful, ill-intentioned, or downright useless. It’s clear that further alignment with human preferences is imperative.
Moreover, while prior research has advocated for the organization of visual instruction tuning samples in multi-turn formats, LVLMs’ capacity to engage effectively is hampered by the feeble connections and limited interdependence between different conversational turns. The true litmus test lies in their ability to adapt responses based on prior context in multi-turn interactions. These dual challenges impede the practical utility of LVLMs as indispensable visual aids.
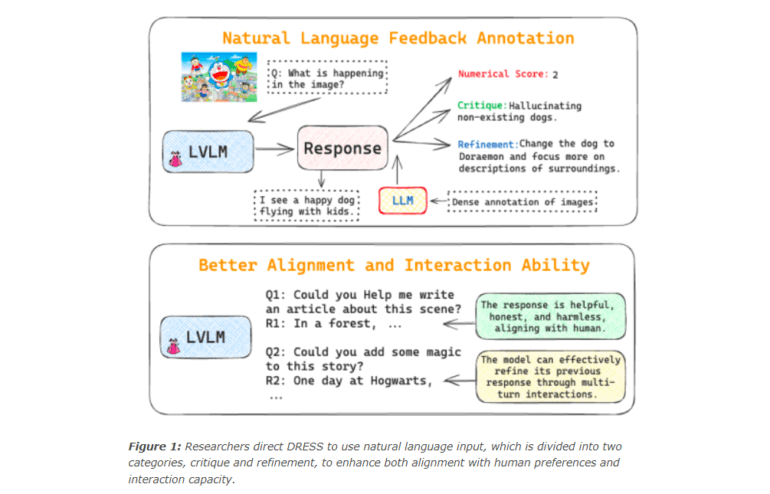
Enter ‘DRESS,’ a remarkable LVLM conceived and nurtured by the collaborative efforts of the research team at SRI International and the University of Illinois Urbana-Champaign. DRESS distinguishes itself by its unique training methodology, which hinges on Natural Language Feedback (NLF) provided by LLMs, as illustrated in Figure 1. The research team directs LLMs to furnish granular feedback on DRESS’s responses, complete with specific guidelines and comprehensive photo annotations. This feedback adheres to the three H criteria: helpfulness, honesty, and harmlessness, mirroring the process of sculpting human-aligned LLMs. It is this feedback that measures the overall quality of responses along these 3H dimensions, assigning both numerical scores and NLF.
The NLF generated is thoughtfully classified into two categories: critique and refinement, a novel categorization approach. While refinement NLF offers precise recommendations to LVLMs, enabling them to fine-tune responses to align with the ground truth reference, critique NLF critically assesses the strengths and weaknesses of the responses. This dual classification unleashes the full potential of NLF, making LVLMs more digestible to human users while elevating their interaction capabilities to new heights.
To overcome the non-differentiable nature of NLF, the research team employs a novel approach, extending conditional reinforcement learning techniques to the training of LVLMs. Specifically, linguistic modeling (LM) loss is used to train DRESS, enabling it to generate responses conditioned on the two NLFs. Through a meticulous analysis of numerical results, DRESS is continually refined to better cater to user preferences. Over the course of multi-turn interactions during inference, DRESS acquires the meta-skill of refining its original responses through the application of refinement NLF.
DRESS’s prowess is rigorously evaluated across a spectrum of scenarios, including multi-turn interactions, adversarial prompting for harmlessness assessment, picture captioning for honesty evaluation, and open-ended visual question responding for helpfulness assessment. The results of these experiments are nothing short of remarkable, with DRESS outperforming its predecessors in aligning with human values and exhibiting superior interaction capabilities. This pioneering effort by the research team marks the first comprehensive approach to addressing the interaction ability and all three 3H criteria for LVLMs, setting a new standard in the field.
Conclusion:
The advent of DRESS, equipped with Natural Language Feedback and advanced training techniques, signifies a pivotal advancement in the LVLM landscape. Its superior alignment with human values and enhanced interaction capabilities hold the promise of revolutionizing industries reliant on visual and textual communication, from customer service to content creation and beyond. Businesses that harness the power of DRESS can expect improved user experiences, increased efficiency, and a competitive edge in the market.